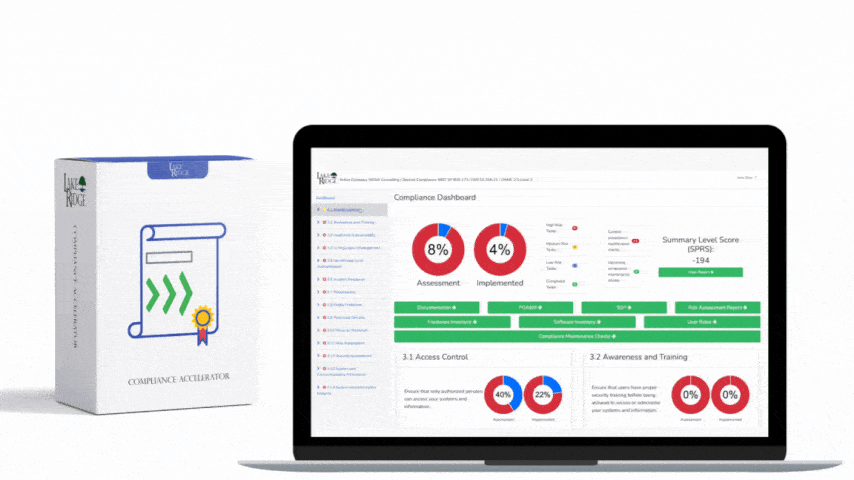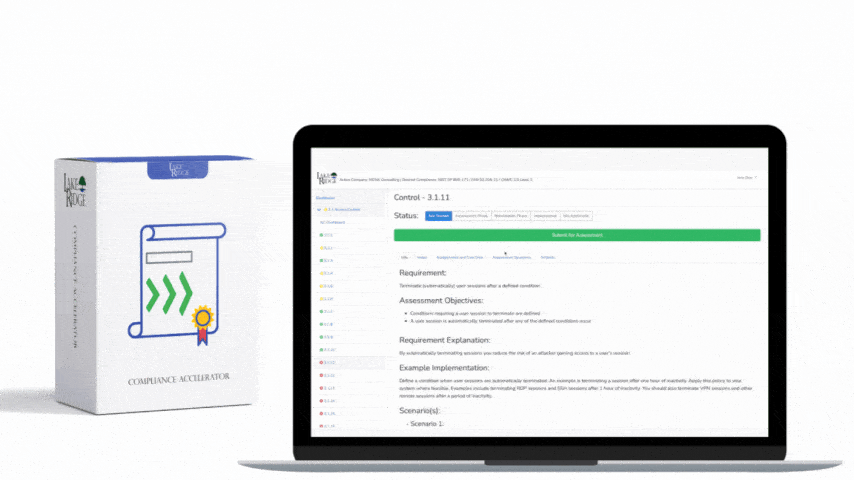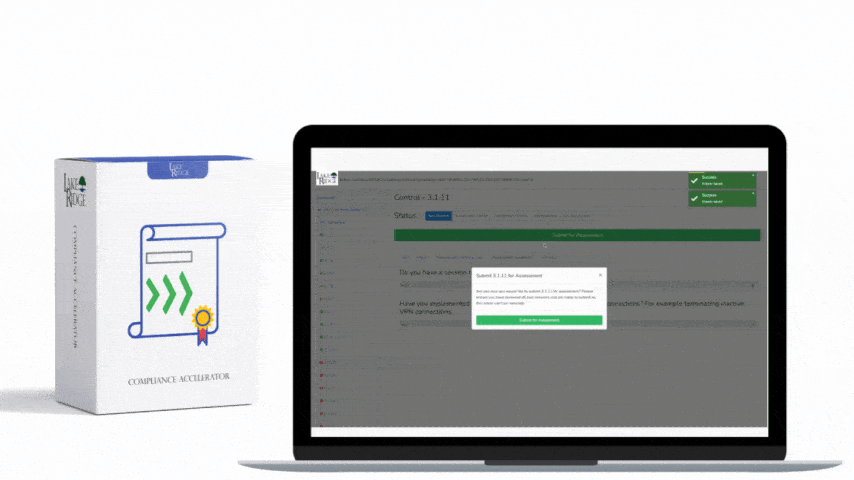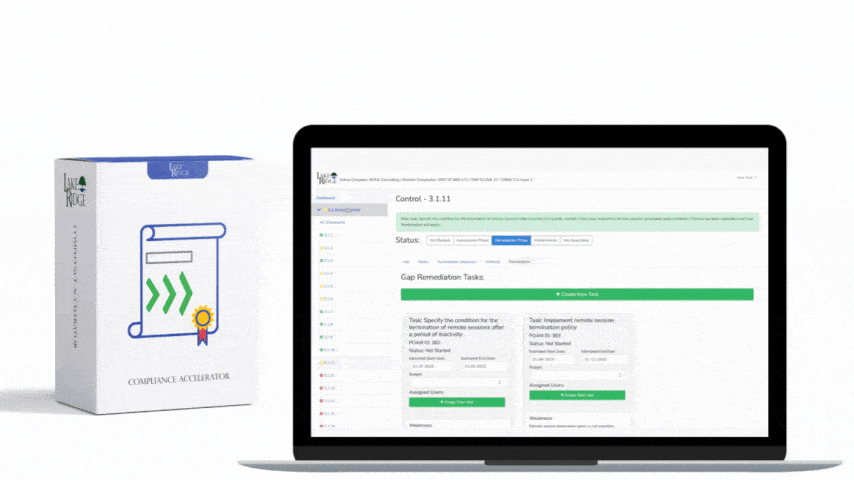
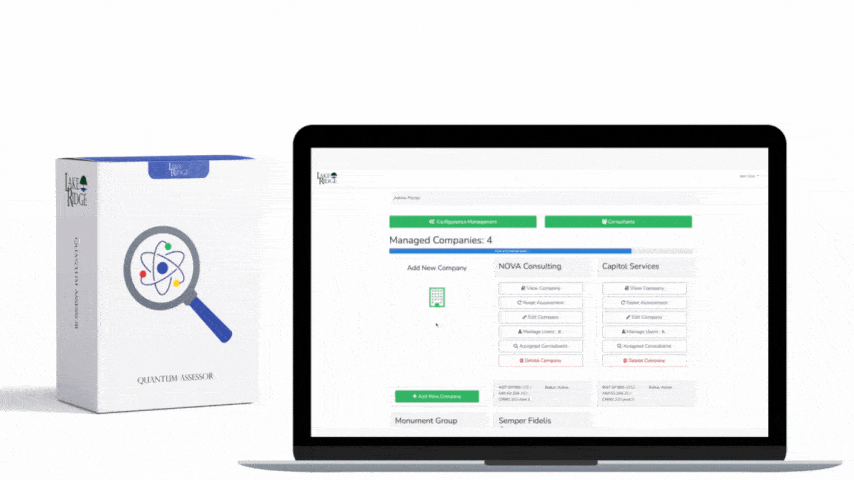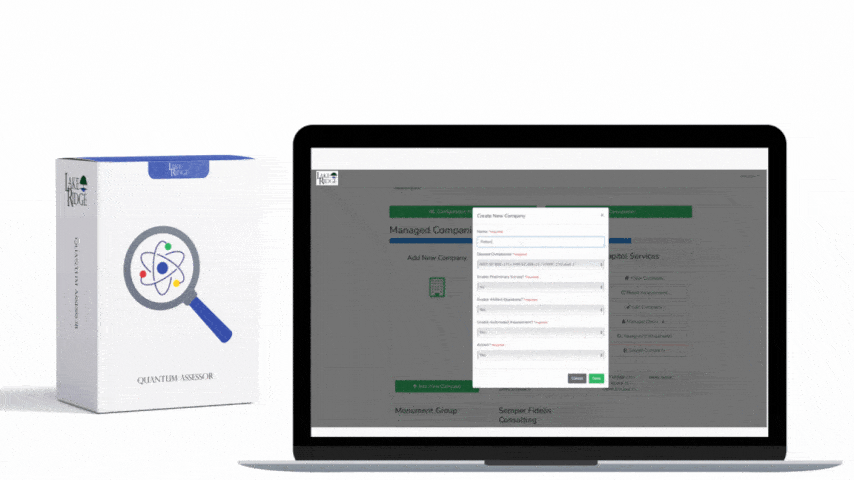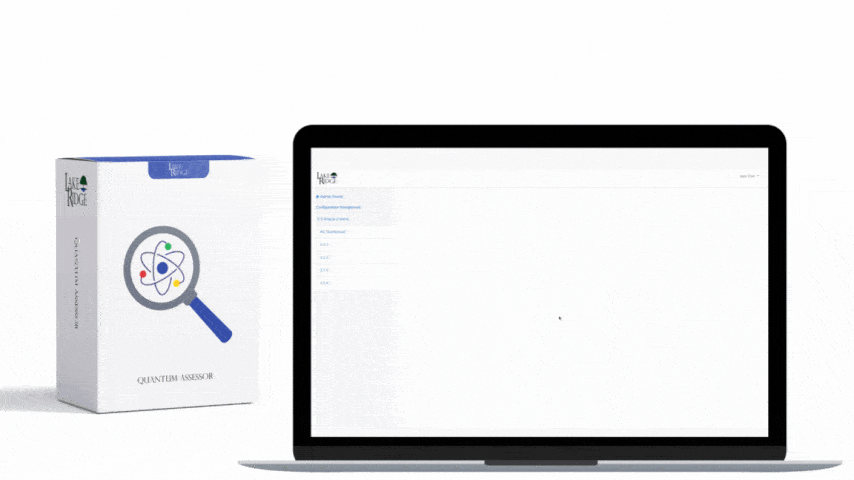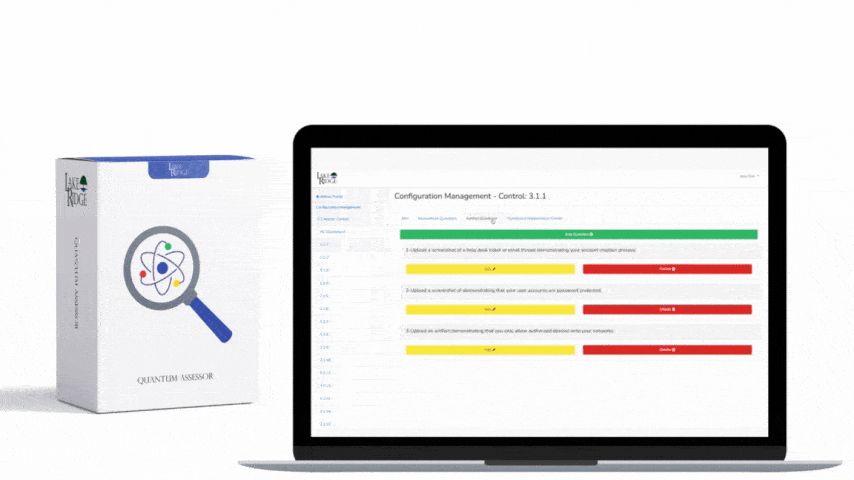
This post shows how to build a practical, auditable incident response (IR) playbook that maps to NIST SP 800-171 Rev.2 / CMMC 2.0 Level 2 control IR.L2-3.6.1, covering preparation through recovery with step-by-step implementation notes, technical controls, and small-business scenarios you can adopt immediately.
Preparation — build the foundation
Start by inventorying CUI-bearing systems and the supporting infrastructure (endpoints, servers, cloud storage, email, VPNs). Assign IR roles (Incident Commander, Forensics Lead, Communications Lead, Legal/Privacy) and publish an IR policy that states scope, escalation criteria, and retention requirements. Technical preparation should include deploying endpoint detection and response (EDR) on all Windows/macOS/Linux endpoints, enabling centralized logging (Syslog/CloudTrail/Windows Event Forwarding → SIEM/Wazuh/Elastic), and creating immutable log storage (AWS S3 with Object Lock or write-once network storage) to preserve chain-of-custody. Document a minimum log retention baseline (e.g., 365 days for CloudTrail, 90+ days for detailed endpoint telemetry) and ensure time synchronization (NTP) across systems for reliable timelines.
Playbook structure and practical implementation notes
Create scenario-based playbooks that map to common incidents: phishing → credential compromise, ransomware on an endpoint, unauthorized cloud data access, and insider misuse. Each playbook should include: (1) detection triggers and required evidence; (2) triage checklist (who must be notified); (3) containment steps with exact commands or UI actions (isolate host from network via EDR, revoke VPN tokens, apply firewall ACL to block external IP); (4) forensic preservation steps (collect memory, export EDR artifacts, snapshot VM disks); (5) eradication and recovery steps; and (6) communication templates (internal, customers, regulators). For small businesses, give operators explicit vendor-agnostic commands or procedures: for example, to isolate a Linux host temporarily, instruct an admin to run "sudo iptables -I OUTPUT -d Define triage criteria and a severity matrix that converts observable indicators into Triage / Incident levels (Low / Medium / High / Critical). Use specific technical signals: multiple failed logins + new privileged account = medium; mass file encryption + AV/EDR alerts = high (ransomware); large outbound transfers of CUI to unknown IPs = critical. Implement SIEM correlation rules and retention of raw logs for at least the triage window; for a small business this could be Elastic + Filebeat + Sysmon or a managed service like AWS GuardDuty + CloudTrail. During analysis, collect IOCs (IPs, hashes, filenames, account names) and build a timeline using accessible artifacts: Windows Event Logs, Sysmon, web proxy logs, CloudTrail, firewall logs, and EDR process/network captures. Use OSQuery or EDR live queries to enumerate running processes, network connections, and scheduled tasks to validate compromise scope. Containment aims to stop damage while preserving evidence. For endpoints, preferred containment actions are EDR host isolation (revoke network access but keep disk accessible), disable the compromised account centrally (Active Directory / IdP), and block malicious IPs at the perimeter firewall. Avoid wiping disks until you have snapshots/images; instead take a disk snapshot (hypervisor snapshot or dd image) and a memory dump (LiME or EDR memory capture). For cloud incidents, immediately rotate service keys, revoke tokens, revoke S3 presigned URLs, and place affected buckets into read-only mode while snapshotting objects. Provide playbook text such as: "Step 1: run EDR isolate; Step 2: create VM snapshot; Step 3: collect memory; Step 4: disable account; Step 5: block IP ranges in firewall and cloud ACLs." These explicit steps make audits and reviews easier and reduce decision-making time during an incident. Decide early whether to rebuild or clean: for suspected persistent threats, a full rebuild from known-good images is safer. Restore from verified backups stored offline or in immutable storage; validate restorations in an isolated test VLAN before rejoining production. Remove backdoors by rotating all credentials, applying security patches, updating EDR/AV signatures, and applying configuration hardening (disable RDP if not needed, enforce MFA, tighten S3 ACLs). Post-recovery validation should include a full scan, monitoring for re-occurrence of IOCs, and a 7–14 day heightened monitoring window. For small businesses using cloud providers, leverage provider snapshots and automated recovery playbooks (Terraform/CloudFormation) to accelerate rebuilding while ensuring configuration drift is addressed. Map every incident to IR.L2-3.6.1 and your organization's system security plan (SSP) to demonstrate alignment during assessment. Record timelines, decisions, evidence collected, and communications; retain these artifacts per contractual requirements (DFARS may require reporting within 72 hours for DoD-related CUI incidents—ensure your playbook includes that cadence and the method (e.g., DoD DIBNet or the designated portal)). Maintain an incident register with MTTD (mean time to detect), MTTR (mean time to respond), and post-incident actions. For audits, produce a one-page incident executive summary, a technical timeline, and an evidence binder (hashes and custody logs for collected artifacts). If required by contract, include notification templates for customers and regulators that include the facts known, systems impacted, and mitigation steps. Tabletop exercises should be run at least twice per year with technical war rooms annually where possible; use real telemetry from dark data and past incidents to make scenarios realistic. After-action reviews (AARs) must be scheduled within two weeks of incident closure and documented with concrete remediation tasks (owner, due date). Track playbook effectiveness with measurable KPIs: time-to-detection, time-to-containment, percentage of incidents requiring rebuild vs. cleanup, and audit findings closed. Update playbooks whenever your environment changes (new SaaS, new identity provider, new backup solution) and store the canonical playbooks in a version-controlled repository accessible to the IR team. Failing to implement IR.L2-3.6.1-style playbooks leaves you exposed to prolonged dwell time, larger extortion payments, unreported CUI loss, contract termination, regulatory fines, and reputational damage. For small businesses holding CUI, this risk is magnified: a single uncontained breach can lead to loss of DoD contracts and downstream liability. Additionally, poor evidence handling can invalidate incident reports during audits, making it impossible to prove timely response and corrective actions. Summary — build playbooks that are short, specific, and practiced: document roles, detection sources, triage rules, containment commands, forensic preservation steps, and recovery procedures. Map playbook artifacts to NIST SP 800-171 / CMMC 2.0 evidence, run regular tabletop and technical exercises, and measure response performance. With these practical building blocks—EDR + centralized logging + scenario-based runbooks + rehearsal—you can meet IR.L2-3.6.1 goals and reduce the operational and compliance risk of cyber incidents.Detection and analysis — convert alerts into validated incidents
Containment — fast, reversible actions with forensics in mind
Eradication and recovery — rebuild with validation and hardening
Reporting, compliance mapping, and documentation
Exercises, metrics, and continuous improvement
Risk of non-implementation