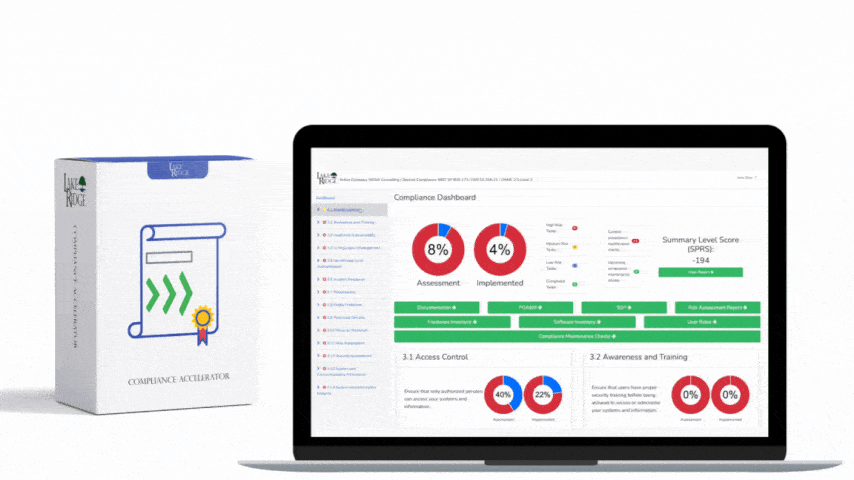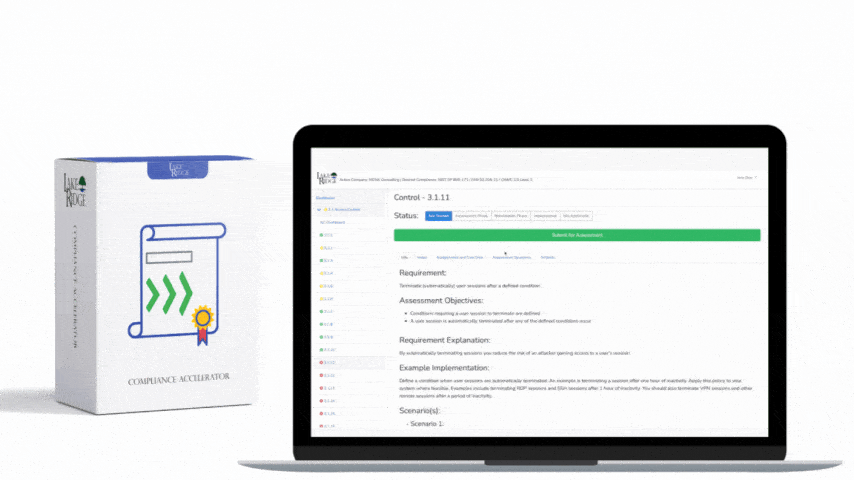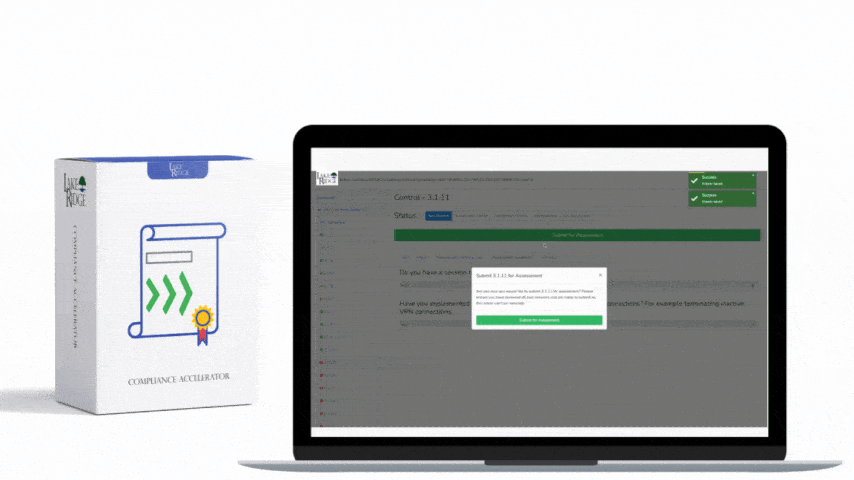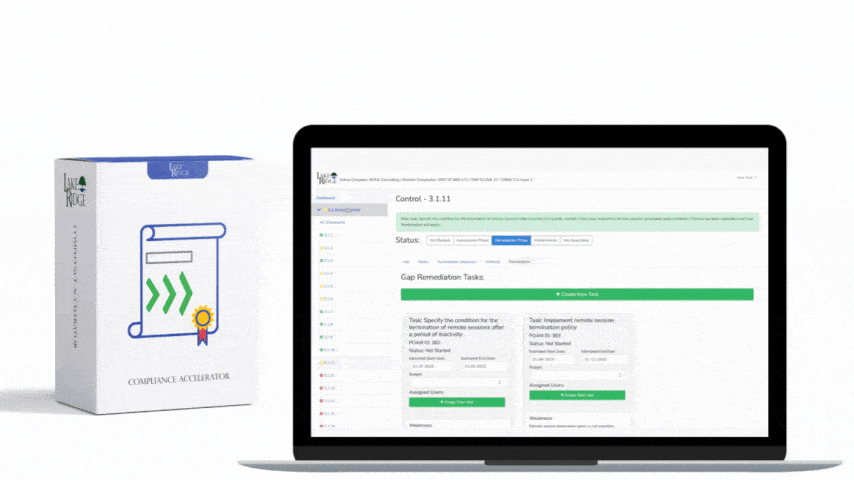
The ECC – 2 : 2024 Control 2-12-1 requires organizations to implement a managed event logging and monitoring program that produces tamper-evident, auditable logs; detects anomalous activity; and supports incident response — this post explains how to build that program, produce audit evidence, and keep it operational for small organizations and enterprises using the Compliance Framework.
What Control 2-12-1 requires (high level and key objectives)
At a high level, Control 2-12-1 focuses on: (1) ensuring critical systems and security components produce useful event telemetry, (2) collecting and centralizing logs with integrity controls and time synchronization, (3) maintaining retention and access controls so logs are audit-preservable, and (4) using monitoring/alerting processes that feed defined incident response workflows. Your compliance objectives are to demonstrate consistent logging coverage, prove logs are unmodified (or tamper-evident), show regular monitoring and tuning, and retain evidence that alerts were triaged and resolved — all documented for an auditor.
Implementation roadmap — scoping, policy and inventory
Start by scoping: create a logging policy aligned to the Compliance Framework stating minimum log types, retention, timezone (UTC), and roles. Build an inventory of systems (critical servers, domain controllers, cloud accounts, network devices, firewalls, endpoints, identity providers, web apps, databases). For each item capture required events (authentication, privilege changes, configuration changes, process creation, firewall accept/deny, admin CLI commands) and map them to minimum log fields: timestamp, timezone, hostname, component, event ID/type, severity, user identity, source/destination IPs, and raw message. That inventory and mapping are primary artifacts auditors will request.
Collection and transport — architecture and technical details
Choose a collection architecture that fits your environment: agent-based (Wazuh/OSSEC, Splunk Universal Forwarder) for endpoints and servers, and agentless (syslog, Windows Event Forwarding) for network devices. Use secure transport (TCP+TLS) for syslog (RFC 5425) or HTTPS for API ingestion. Example configs: rsyslog with TLS — set ActionQueueType LinkedList and ActionResumeRetryCount to avoid drops; for Windows use a collector (Windows Event Forwarding) that forwards to a hardened collector VM. In cloud, enable provider-native sources (AWS CloudTrail, VPC Flow Logs, Azure Activity Logs) and forward to a centralized store like S3/Blob with encryption, then ingest to your SIEM. Ensure all collectors and log servers have NTP/chrony configured and monitored to ±1s to preserve event sequencing for forensic analysis.
Normalization, storage, retention, and integrity
Normalize logs into a consistent schema (timestamp in UTC, canonical user fields, normalized severity). Store logs in at least two tiers: hot (searchable, e.g., ELK indices or Splunk indexers) for 30–90 days and cold (immutable archive) for the remainder of your retention schedule. For audit-readiness implement tamper evidence: enable object-lock/WORM on S3 buckets or use write-once storage, produce regular SHA-256 manifests of archived files, and store manifests separately (and signed) — e.g., generate a manifest daily with sha256sum and store the manifest in a different S3 bucket with MFA-delete enabled. Encrypt logs at rest (e.g., KMS) and in transit (TLS), and restrict access with least-privilege IAM roles and role separation (ops vs. security vs. auditors).
Detection, alerting, and integration with incident response
Define your detection use-cases against the Compliance Framework outcomes: failed logon storms, privilege escalations, abnormal data exfil, configuration changes to security controls, and lateral movement patterns. Implement alerts in the SIEM with clear priority levels, and connect them to playbooks that define triage steps, evidence collection, escalation criteria, and timelines. For small teams, document and test one or two high-value playbooks (e.g., compromised credential and data exfil) and use automation (e.g., CloudWatch Event Rules + Lambda, or SOAR playbooks) to perform containment actions like blocking IPs or disabling accounts. Keep alert rules versioned in source control and produce an "alert tuning" log demonstrating weekly/monthly tuning to reduce false positives — auditors want to see ongoing maintenance.
Small business examples and cost-effective patterns
Small businesses can meet Control 2-12-1 without large budgets: use a managed SIEM/MSSP or an open-source stack (Wazuh + ELK + OpenSearch) hosted on cloud VMs. Example: enable AWS CloudTrail and VPC Flow Logs, send to encrypted S3 with lifecycle rules, enable CloudWatch metric filters for key detections and send notifications to an on-call channel; use S3 Object Lock for 365-day immutability and store daily SHA-256 manifests in a separate bucket. For on-premises, deploy a single hardened log collector VM running rsyslog and Filebeat to forward to a central OpenSearch cluster; schedule daily cron jobs to hash archived logs and push manifests to a Git repo with branch protection for auditors. Small teams should prioritize domain controllers, VPN gateways, email, and edge firewalls first — those provide the highest signal for incident detection and compliance evidence.
Compliance tips, testing, audit evidence, and risks of non-implementation
Practical compliance tips: document everything (policy, architecture diagrams, log source matrix, retention schedule), automate evidence collection (monthly export of log source list and sample logs), and run quarterly tabletop exercises that reference your alert playbooks. For audits prepare: (a) the logging policy, (b) the inventory and mapping spreadsheet, (c) a recent integrity manifest and verification logs, (d) SIEM detection rules and tuning history, (e) incident tickets tied to alerts showing triage and resolution, and (f) time-sync and backup proofs. The risk of not implementing this control is high: missed compromises and delayed detection, incomplete forensics, regulatory fines, and damage to reputation. From an operational risk view, poor logging means you cannot prove reasonable due care, which increases legal and insurance exposure.
Summary: Build your Control 2-12-1 program by scoping assets, standardizing log schemas, securing collection and transport, ensuring immutability and retention, tuning detection, and documenting evidence; small organizations can leverage cloud-native services and open-source stacks to be audit-ready. Start with a logging policy, an inventory of critical sources, and one tested detection-playbook — those three artifacts will deliver immediate compliance value and form the backbone of an auditable, defensible logging and monitoring program under the Compliance Framework.