This post shows a practical, implementable approach to satisfy CA.L2-3.12.3 (the continuous monitoring/control assessment expectation in NIST SP 800-171 Rev.2 / CMMC 2.0 Level 2) by building an automated pipeline that combines SIEM and EDR telemetry, detection logic, and response playbooks — tuned for small-business constraints and real-world operations.
Understanding CA.L2-3.12.3 and the compliance objective
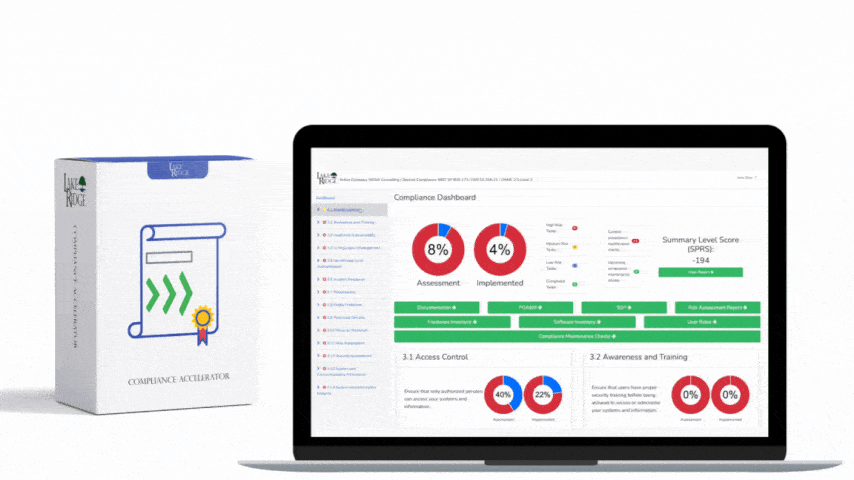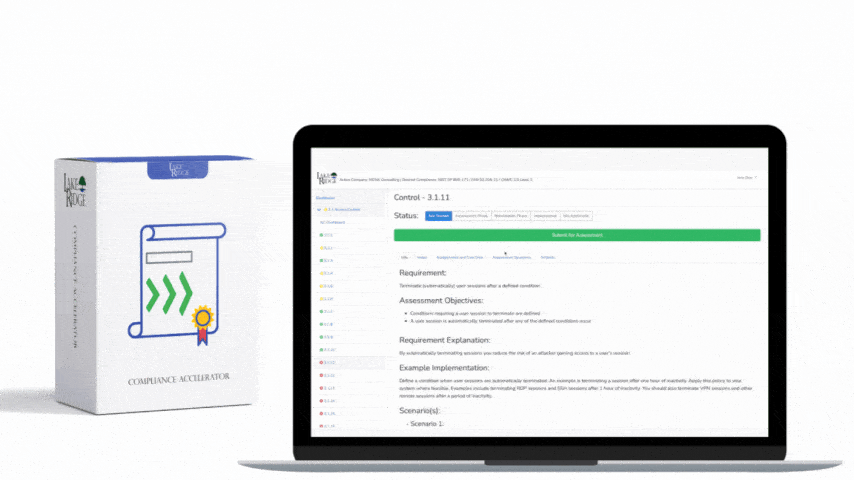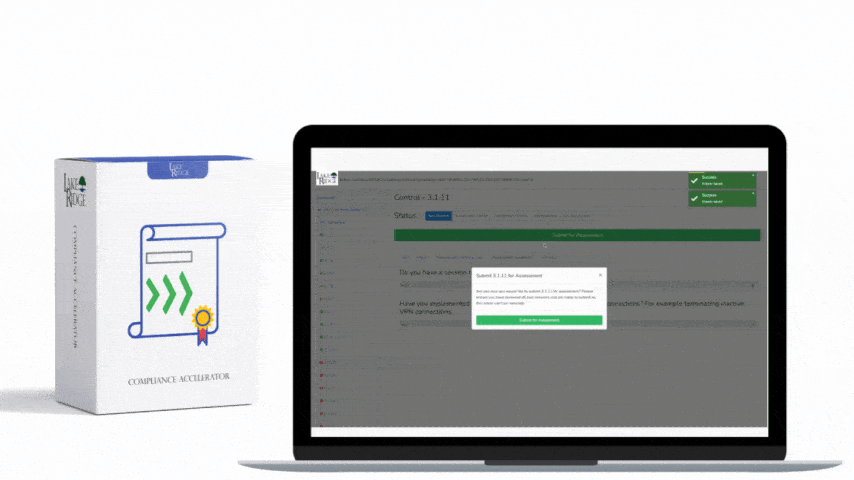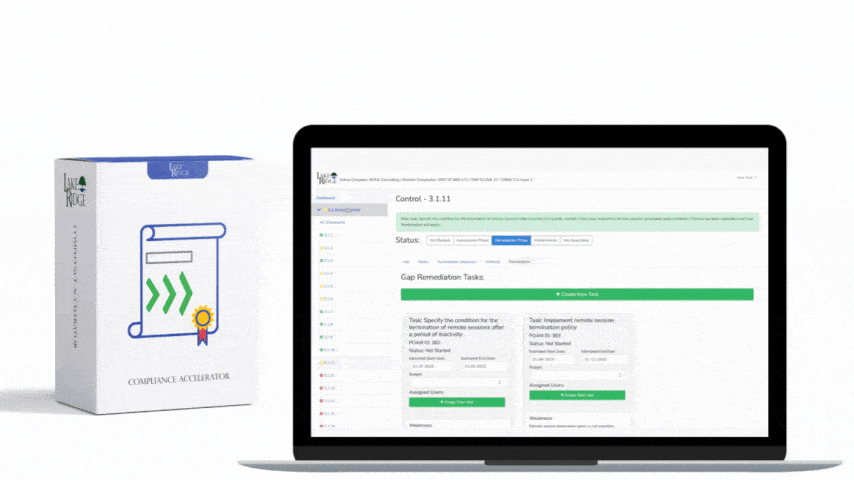
At a high level CA.L2-3.12.3 requires an organization to have continuous monitoring and assessment capabilities that detect deviations, track security posture, and provide evidence that controls are working. For small businesses handling CUI, this means collecting relevant telemetry, running automated detections, generating auditable alerts and reports, and retaining evidence for assessments. The pipeline described here maps directly to that expectation: ingest logs and EDR telemetry, normalize and correlate in a SIEM, generate prioritized alerts, automate containment actions where safe, and retain show-and-tell artifacts for auditors.
What telemetry to collect (practical list)
Collect telemetry that demonstrates control effectiveness and supports incident detection: Windows event logs (System, Security, Application), Sysmon (event IDs 1 process create, 3 network connect, 7 image loaded, 11 filecreate, 22 DNS), Linux auditd and syslog, EDR process/registry/network telemetry, proxy and web gateway logs, VPN/authentication logs (RADIUS, AD/LDAP), cloud control-plane logs (AWS CloudTrail, Azure Activity), NetFlow/Zeek for lateral movement/exfil, and vulnerability scanner results. For each source, capture timestamp (NTP-synced), host asset ID, user identity, process command-line, parent process, and network endpoint info so correlating rules can reliably link events.
Designing the automated monitoring pipeline
Design the pipeline in stages: (1) log/telemetry collection agents (Winlogbeat/Sysmon, filebeat, EDR sensor), (2) secure transport (TLS to collectors or via agent direct API), (3) normalization and enrichment (use ECS or CEF fields, append asset owner from CMDB, geo/IP enrichment), (4) detection and correlation in SIEM (correlate process events + network flows + auth failures), (5) automated response orchestration (SOAR or native EDR actions), and (6) evidence storage and reporting (immutable snapshots, chain-of-custody metadata). For small business resource constraints, prioritize critical hosts (domain controllers, CUI servers, developer laptops) and cloud control-plane logs first, then expand coverage.
Small-business implementation scenarios
Example A (small on-prem shop): Deploy Sysmon + Winlogbeat on 50 Windows endpoints, collect to an Elastic Stack SIEM hosted on a single VM, integrate with an EDR (Microsoft Defender or CrowdStrike) that forwards telemetry via API. Create 15 core correlation rules (suspicious cmd.exe strings, anomalous RDP logins, new service creation, large outbound transfers) and auto-create tickets in Jira. Example B (cloud-first small business): Use Microsoft Defender for Endpoint + Azure Sentinel; forward CloudTrail and VPC flow logs to Sentinel; implement automated playbooks that isolate a VM, block offending IPs in NSG, and collect forensic snapshot to a storage account for auditor review. If you lack staff, contract a vetted MSSP for 24x7 alert triage while keeping control of long-term log retention and access controls.
Technical implementation details and specifics
Concrete technical steps: install Sysmon with a conservative config that logs process creation (1), network connect (3) and image loads (7); forward those events via Winlogbeat to the SIEM. Configure EDR to record and forward process GUIDs, parent IDs, file hashes, and command-lines; ensure the EDR API provides a reliable stream or push mechanism. Implement parsing rules in the SIEM to map: sysmon.EventID -> event.type, EDR.process.command_line -> process.args, source.ip/dest.ip -> network.direction fields. Use threat intelligence throttling and enrichment feeds to append known-malicious indicators. Ensure all agents use mutual TLS, host certificates, and are validated by a central management server to prevent rogue agents spoofing logs.
Detection rules and response playbooks
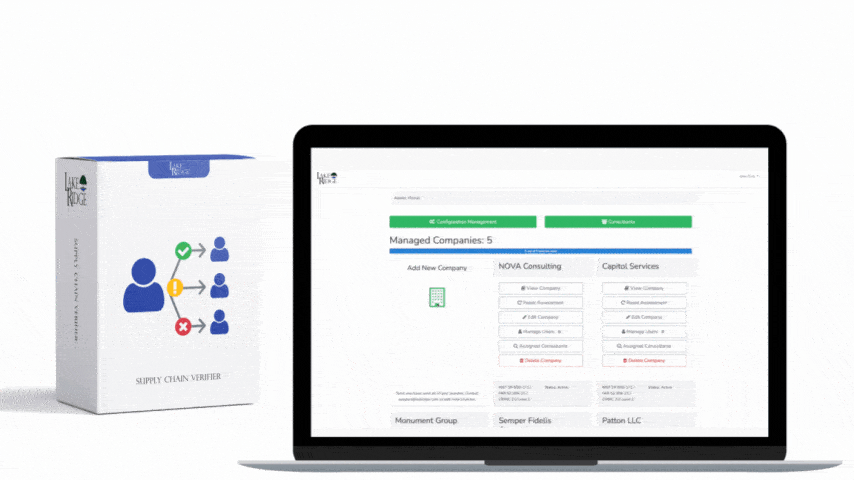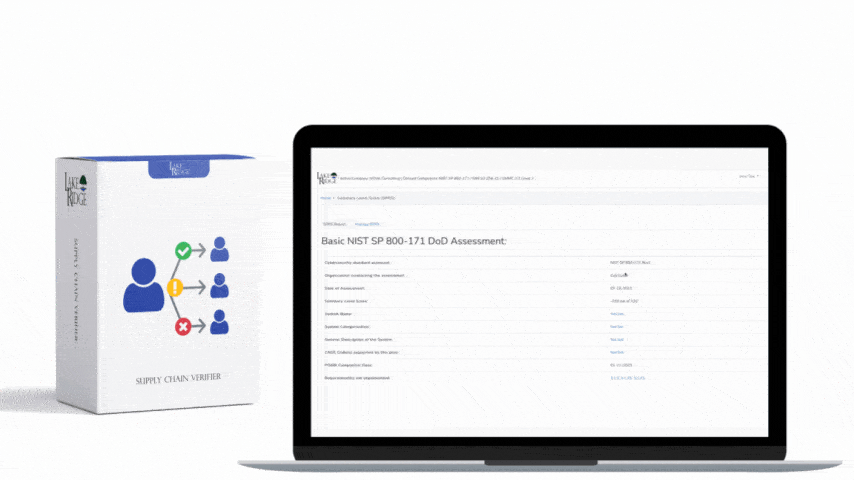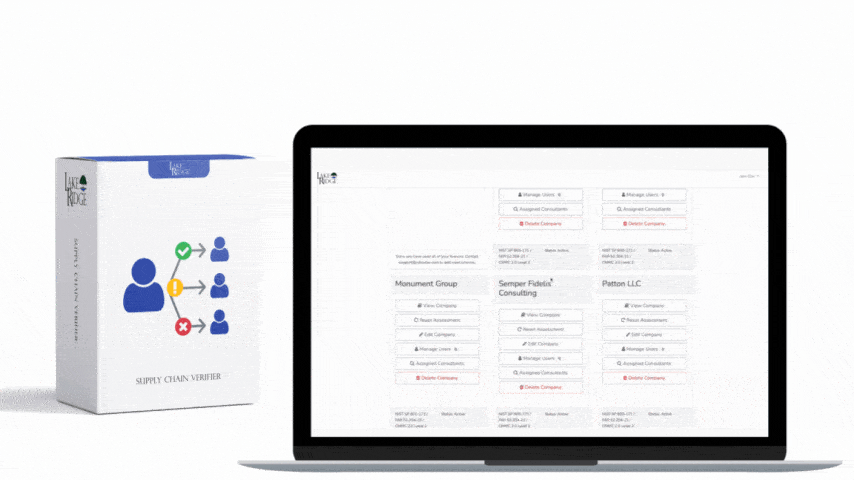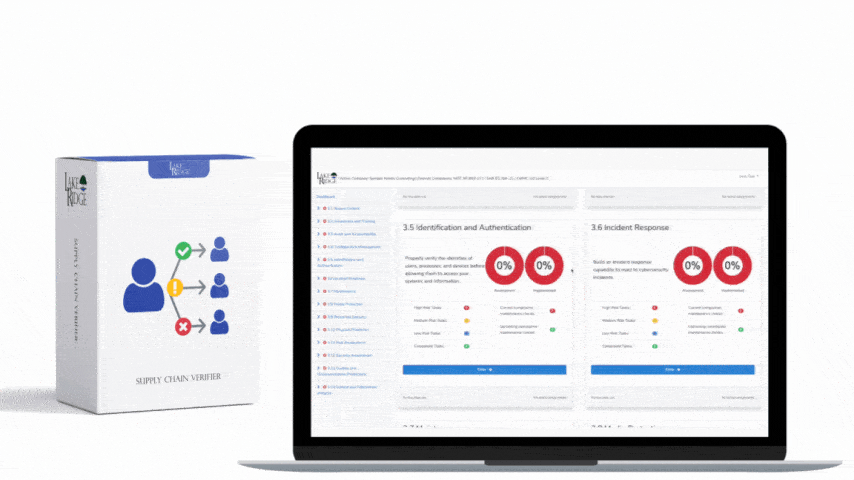
Start with high-fidelity detections: (1) Process creation where parent is Explorer or Winlogon but process is PowerShell with encoded commands — treat as high priority; (2) New service/driver creation on non-admin asset types; (3) Lateral movement: NTLM pass-the-hash patterns, sequential failed logins + successful remote execution; (4) Data exfil: large outbound transfer > threshold + use of non-corporate ports or DNS tunneling signatures. For each detection, build a playbook: enrich alert with asset owner and vulnerability age, attempt automated containment (EDR isolate host), take forensic snapshot (EDR collect), create ticket and notify DPO and affected business owner. Validate playbooks in a staging environment to avoid disruption (e.g., isolate only after confirmation for production critical hosts unless runbook explicitly allows automated isolation).
Risk of not implementing and why this matters
Without an automated monitoring pipeline you risk delayed breach detection (days to months), uncontrolled exfiltration of CUI, failure during CMMC/DFARS assessments, contract loss, reputational damage, and potentially regulatory fines. Small businesses are attractive targets because they often lack detection capabilities; a single missed lateral movement or a rogue admin credential can lead to a supply-chain compromise. From a compliance perspective, lack of demonstrable continuous monitoring is a common deficiency during assessments and can result in corrective action plans that disrupt business.
Compliance tips and best practices
Map each detection and log source back to the Compliance Framework controls and include that mapping in your evidence pack. Maintain playbook and detection testing records (purple-team exercises) as auditor evidence. Keep time synchronization across all systems (NTP), enforce agent tamper protection and integrity checks, and use role-based access to SIEM/EDR consoles. Define minimum retention (e.g., 90 days hot, 1 year archive for critical log types) based on contract requirements and available storage. Finally, automate report generation that shows uptime of collection pipelines, detected incidents with timelines, and remediation status so assessors see continuous monitoring in action.
Summary: Implementing CA.L2-3.12.3 is achievable for small businesses by building a pragmatic SIEM+EDR pipeline: collect prioritized telemetry, normalize and correlate, implement a small set of high-fidelity detections, automate safe containment and evidence capture, and maintain auditable evidence and mapping to the Compliance Framework. Start small, iterate, and use managed services for 24x7 coverage if in-house staff is limited — the key is demonstrable, repeatable monitoring and response that you can show during NIST/CMMC assessments.