This implementation guide explains how to configure a Security Information and Event Management (SIEM) system and alerting to meet the Essential Cybersecurity Controls (ECC – 2 : 2024) Compliance Framework requirement Control 2-12-2 for event logs and monitoring management, with concrete steps, sample detection logic, and small-business scenarios.
Understanding Control 2-12-2 and Compliance Framework Expectations
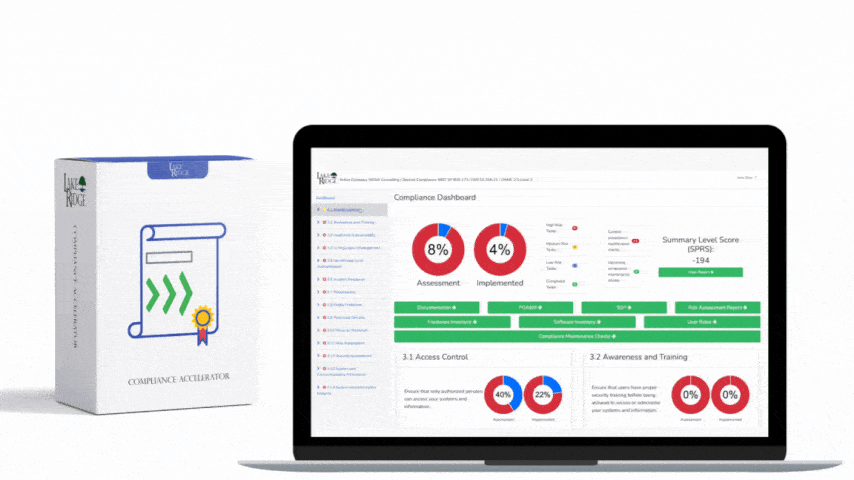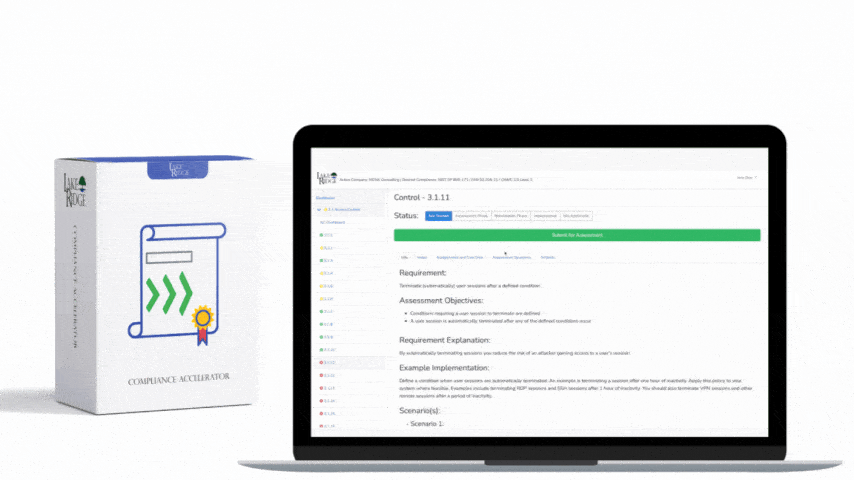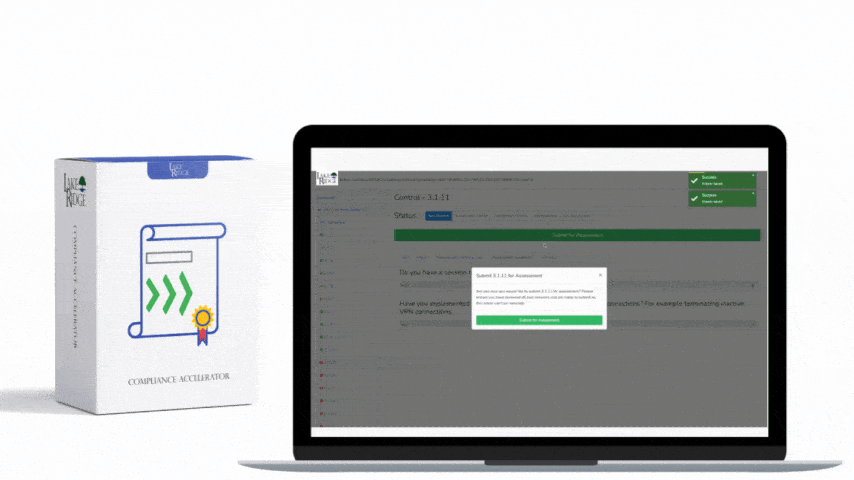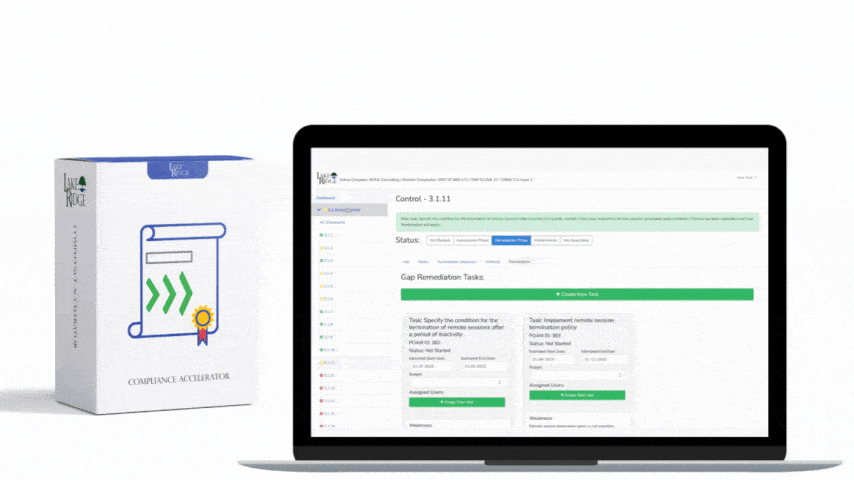
Control 2-12-2 in ECC – 2 : 2024 requires centralized collection, retention, and actionable alerting for security-relevant event logs in order to detect, investigate, and respond to potential security incidents. For Compliance Framework assessments this means demonstrable evidence of: (1) defined log sources and retention policy, (2) reliable log ingestion into a central monitoring platform (SIEM), (3) documented alerting/use cases mapped to risk, and (4) an operational process for triage, escalation, and forensic preservation. Your implementation must be auditable — configuration screenshots, runbooks, and test logs help verify compliance.
Practical Implementation Steps
1. Inventory and prioritize log sources
Start by creating a log-source inventory mapped to business risk and compliance needs: domain controllers, authentication systems (AD/LDAP, SSO), endpoint agents, firewalls, VPN gateways, email security, web and application servers, databases, and cloud audit logs (AWS CloudTrail, Azure Activity Logs, GCP Audit Logs). For a small business (10–50 employees), prioritize AD authentication logs, firewall/NAT, VPN, critical application logs (e.g., POS or payment), and endpoint EDR alerts. Document source, owner, retention needs, and log format (syslog, Windows Event, JSON, API).
2. Design SIEM architecture and sizing
Choose an architecture that fits your scale and Compliance Framework constraints: centralized collector + indexers for larger shops, or a cloud/SaaS SIEM (e.g., Elastic Cloud, Splunk Cloud, Microsoft Sentinel, Chronicle) for smaller operations. Key technical details: collectors should use TLS mutual auth for transport, use buffering for network interruptions, and have high-availability where needed. Estimate ingestion rate (GB/day) to size storage: small businesses often start at 1–10 GB/day. Define hot/warm/cold storage tiers and retention — Compliance Framework may require demonstrable retention; a common pattern is 90 days of hot search and 1 year archived depending on policy.
3. Implement reliable log collection and forwarding
Use native collectors where possible: Windows Event Forwarding (WEF) to a forwarder, syslog-ng/rsyslog for *nix, cloud-native agents for cloud provider logs, and unified agents (Wazuh/Elastic/OSQuery/EDR) on endpoints. Configure structured logging (JSON) for apps. Ensure timestamps are normalized to UTC and time sync (NTP) is enforced across systems. Secure transport: syslog over TLS, HTTPS API with mutual TLS, or agent encryption. For evidence of compliance, capture architecture diagrams and forwarding configs (rsyslog.conf, nxlog, WinEvent forwarding subscriptions).
4. Normalize, parse, and enrich events
Normalization is essential for correlation and consistent alerting: implement parsers (Grok, pipeline processors, or built-in SIEM parsers) to extract fields like src_ip, dst_ip, user, event_id, and status. Enrich logs with asset ownership, business criticality tags, geolocation, and threat intelligence (malicious IP lists, CVE mappings). Map events to MITRE ATT&CK tactics/techniques for traceability in audits. Example: convert Windows Event 4625 (failed logon) into fields: failure_reason, account_name, src_ip, logon_type.
5. Build actionable alerting and detection rules
Translate risk scenarios into prioritized use cases and detection rules. Start with high-value detections: multiple failed logons across accounts from same IP, successful admin logons outside business hours, lateral movement indicators, privilege escalation events, data exfiltration anomalies, and endpoint execution of suspicious binaries. Keep detection logic specific and measurable — for example, a Splunk-style detection for brute-force:
index=wineventlog EventCode=4625 | stats count by src_ip, Account_Name | where count > 10event.code: "4625" and event.outcome: "failure" | group by source.ip count > 106. Tune to reduce noise and establish incident workflows
Tuning is continuous: implement baseline thresholds, rate limiting, and suppression windows to reduce false positives. Use allowlists for known scanners and internal automation accounts. Define SLA for alert investigation (e.g., triage within 15 minutes for critical, 4 hours for high) and maintain playbooks for each detection. For small businesses with lean security teams, automate enrichment (WHOIS, passive DNS) and initial triage via scripts or SOAR playbooks to accelerate response while logging actions for compliance evidence.
Real-world Small Business Scenarios
Example 1 — Small retail shop (POS + 12 staff): Configure POS servers and payment gateways to forward logs to a lightweight SIEM (Elastic + Filebeat). Monitor POS process crashes, unexpected outbound connections, and failed admin logins. Keep 90 days of searchable logs and 1 year archived. Example 2 — Legal firm (20 employees): Prioritize AD logs, VPN, email gateway, and file server access. Detect unusual file downloads or mailbox forwarding rules. Create a detection that triggers when a user creates a mail forwarding rule plus downloads >1 GB from file shares within 24 hours. Example 3 — SaaS startup (50 employees): Leverage cloud SIEM (Sentinel) to centralize CloudTrail, EKS, and app logs; alert on new IAM key creation and privilege modifications during off-hours with automated ticket creation and quarantining of keys via IaC rollback processes.
Risk of Not Implementing Control 2-12-2
Failure to centralize logs and implement effective alerting leaves organizations blind to lateral movement, credential theft, and exfiltration. For Compliance Framework assessments, missing this control can lead to failed audits, contractual penalties, and increased insurance costs. Operationally, lack of central logs increases mean time to detect (MTTD) and respond (MTTR), often turning recoverable incidents into data breaches with reputational and regulatory consequences.
Summary: Implementing ECC – 2 : 2024 Control 2-12-2 requires a disciplined approach—inventory and prioritize log sources, design a secure SIEM architecture, ensure reliable collection and parsing, codify detection use cases with actionable alerts, and maintain tuning and incident workflows. For small businesses, choose scalable solutions (cloud SIEM or lightweight stack), document configurations and runbooks for Compliance Framework evidence, and prioritize automation to compensate for limited staff. Proper implementation significantly reduces risk and establishes a demonstrable, auditable monitoring posture.