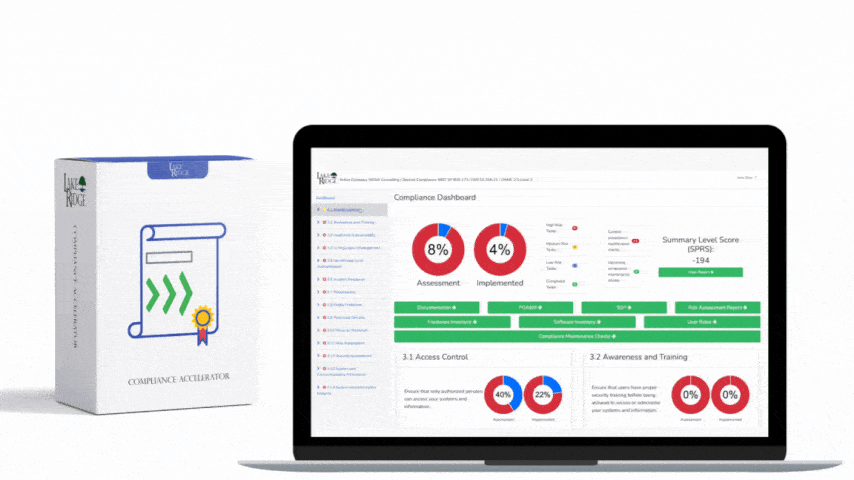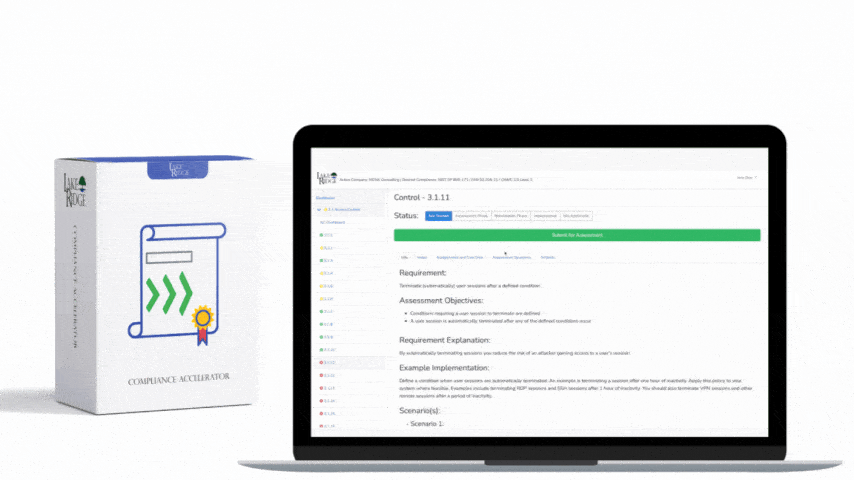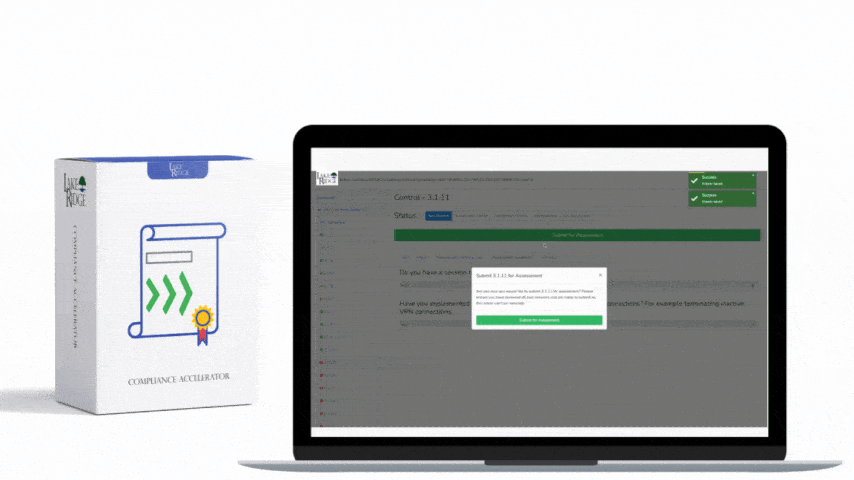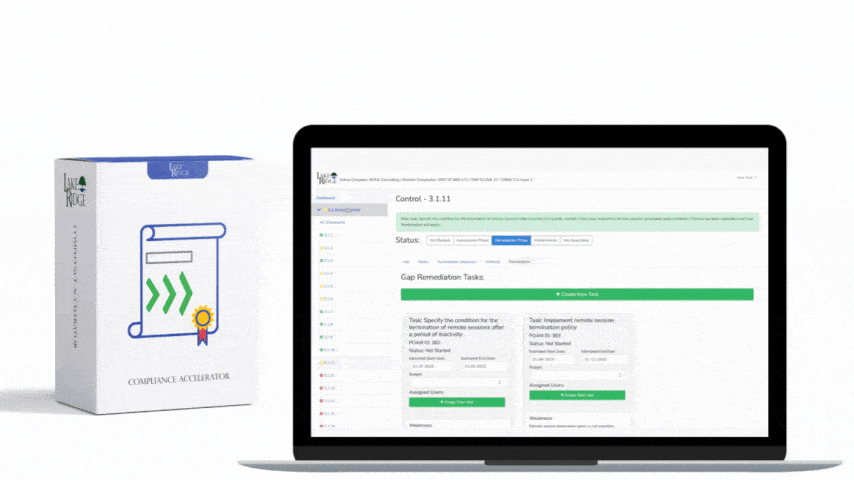
Continuous monitoring is the operational backbone for meeting CA.L2-3.12.3 under NIST SP 800-171 Rev.2 / CMMC 2.0 Level 2: it ensures your environment's security posture is visible, measurable, and actionable in near real-time—this post provides a step-by-step playbook with tools, processes, real-world small business examples, and a practical checklist to implement an effective program.
Understanding Control CA.L2-3.12.3
At its core, CA.L2-3.12.3 requires organizations to continuously monitor and assess system security status so that changes, vulnerabilities, and anomalous activity are detected and addressed promptly. For small businesses handling CUI or subject to DFARS clauses, this means establishing logging, telemetry collection, vulnerability scanning, configuration drift detection, and a documented process for evaluating and responding to alerts. The objective is not perfect coverage but consistent, risk-based observability and response that demonstrates due care and control over your systems.
Key Components of a Continuous Monitoring Playbook
Tools: what to deploy
Practical tool choices depend on budget and complexity. For cloud-heavy small businesses, leverage cloud-native telemetry (AWS CloudTrail, CloudWatch + GuardDuty, Azure Monitor + Sentinel) for basic continuous monitoring; augment with a SIEM (commercial or open-source like Wazuh/Elastic) to centralize logs, create correlation rules, and retain logs for audits. Deploy endpoint detection and response (EDR) agents (CrowdStrike, Microsoft Defender for Endpoint, or open-source agents), network flow collectors (NetFlow/Zeek), and schedule automated vulnerability scans (Tenable, Qualys, Nessus, or OpenVAS). Implement configuration management and drift detection with tools like Ansible/Chef + CIS benchmarks and host integrity checks (AIDE, Tripwire).
Processes: how it should run
Define a cycle: data collection → normalization → detection → triage → remediation → reporting. Example cadence: continuous log ingestion, daily automated vulnerability scans, weekly configuration drift reports, and monthly full security posture reviews. Create clear alerting thresholds (e.g., detect high anomalous process creation, repeated failed authentications, or CVSS ≥ 7 vulnerabilities on internet-facing assets) and SLAs: acknowledge alerts within 1 hour, triage within 4 hours, remediate critical vulnerabilities within 14 days or apply compensating controls. Document these SLAs in the playbook so internal reviewers and external assessors can verify consistent application.
Roles, Metrics, and Automation
Assign roles: System Owner (asset accountability), ISSO/Compliance Lead (policy/controls), SOC Analyst or outsourced MSSP (monitoring and triage), IT Ops (remediation and patching), and Executive Sponsor (risk decisions). Track metrics that demonstrate program effectiveness: mean time to detect (MTTD), mean time to remediate/contain (MTTR), percent of assets with current EDR, weekly vulnerability scan coverage, number of high/critical findings trending down, and log source coverage percentage. Automate playbook steps where possible—use SOAR or scripts to enrich alerts with asset inventory, run vulnerability scans, open tickets in ITSM, and deploy emergency patching jobs when safe.
Small Business Scenarios and Real-World Examples
Scenario A — Small DoD subcontractor with limited staff: Use AWS CloudTrail + GuardDuty and enable GuardDuty findings to forward to a lightweight SIEM (Wazuh or Elastic Cloud). Outsource 24/7 triage to an MSSP for alerting and keep remediation in-house with documented SLAs. Example action: a GuardDuty “Recon:EC2/PortProbe” triggers enrichment with asset tags, opens a Jira ticket assigned to an engineer, and schedules a 2-hour containment window.
Scenario B — On-premises small engineering firm: Install EDR on all endpoints, run weekly Nessus scans against a segmented CUI subnet, and use OSSEC/AIDE for file integrity. If a critical vulnerability (CVSS 9.0) is found on a domain controller, the playbook escalates to the ISSO, isolates the host via network quarantine (via NAC or switch ACLs), and initiates recovery using a tested image to reduce MTTR and preserve forensic artifacts.
Implementation Checklist
Use the following checklist as a practical start—implement items iteratively and document evidence for audits:
- Define scope and document systems that process/store CUI; map to asset inventory.
- Enable centralized logging (syslog/CloudWatch/Log Analytics) and enforce TLS + encryption at rest.
- Deploy an EDR solution across all endpoints and verify agent coverage ≥ 95%.
- Install a SIEM or log aggregator; create baseline dashboards for authentication, elevation, and network anomalies.
- Schedule automated vulnerability scans (internal weekly, external monthly) and document scanning windows and exclusions.
- Implement configuration management and periodic drift detection against CIS benchmarks.
- Define detection rules mapped to MITRE ATT&CK and CMMC objectives; prioritize high-confidence actionable alerts.
- Create incident triage runbooks: alert enrichment, initial containment steps, forensic preservation, remediation, and post-incident review.
- Set SLAs for acknowledgement, triage, and remediation by severity and track via dashboards/ticketing system.
- Conduct quarterly tabletop exercises and annual red-team or penetration tests to validate monitoring efficacy.
Risks of Not Implementing Continuous Monitoring
Failing to implement CA.L2-3.12.3-style monitoring leaves CUI and other sensitive assets blind to compromises and misconfigurations. Consequences include undetected exfiltration, prolonged dwell time for attackers, failure to meet contract requirements, loss of contracts, regulatory penalties, and reputational harm. From a technical perspective, lack of monitoring increases the likelihood of lateral movement, persistence, and failure to detect critical vulnerabilities before exploitation.
Compliance Tips and Best Practices
Keep evidence organized: timestamped logs, SIEM rule descriptions, remediation tickets, and patch reports—these are what assessors will request. Use risk-based prioritization: focus on internet-facing systems, CUI repositories, and privileged accounts first. Leverage templates: maintain playbooks with checklists for each alert type (malware, failed backups, configuration drift). For small teams, prefer cloud-native tooling or an MSSP to reduce operational burden, and codify everything so that personnel changes don't break the process. Finally, map monitoring artifacts back to control language (rule IDs, scan reports, and SLAs) to demonstrate compliance traceability.
In summary, CA.L2-3.12.3 compliance is achievable for small businesses by combining a limited set of practical tools, clear processes, defined roles, and measurable metrics; start with an asset-focused scope, implement centralized logging and EDR, automate enrichment and ticketing, define SLAs, and use the checklist above to build a repeatable, auditable continuous monitoring program that reduces risk and proves control effectiveness.