This post explains how to implement continuous network monitoring to satisfy Compliance Framework ECC – 2 : 2024 Control 2-5-2 (SIEM, IDS/IPS and Alerting Playbook), combining practical SIEM and IDS/IPS configuration guidance, an operational alerting playbook, and small-business examples so you can create an auditable, repeatable program that reduces dwell time and meets compliance objectives.
Implementation overview: what Control 2-5-2 requires in practice
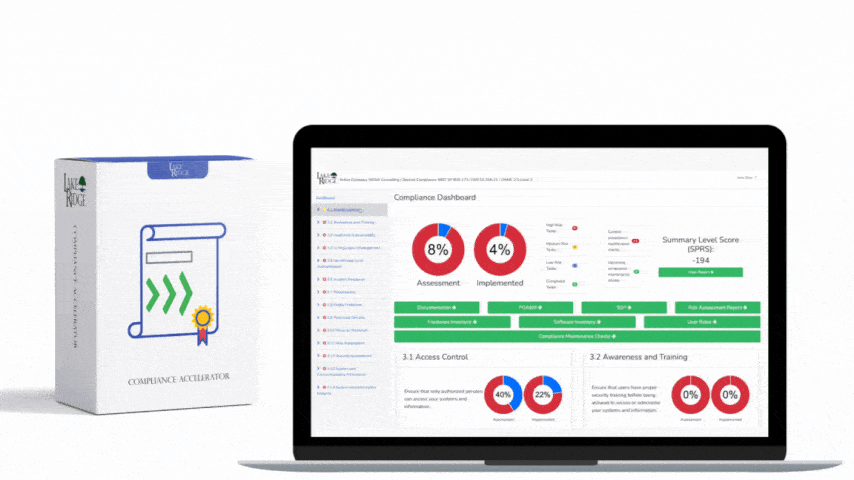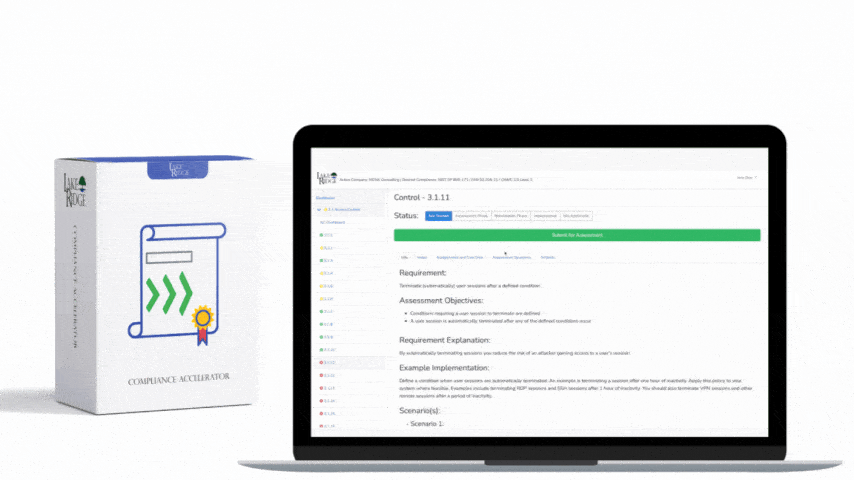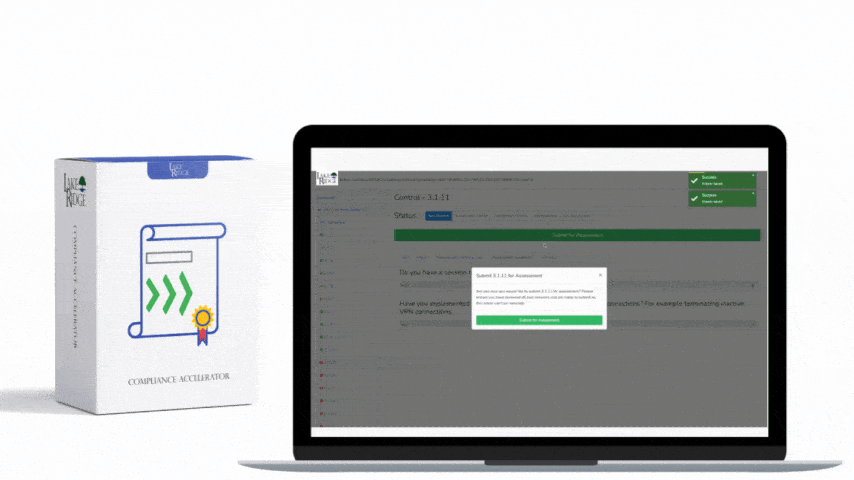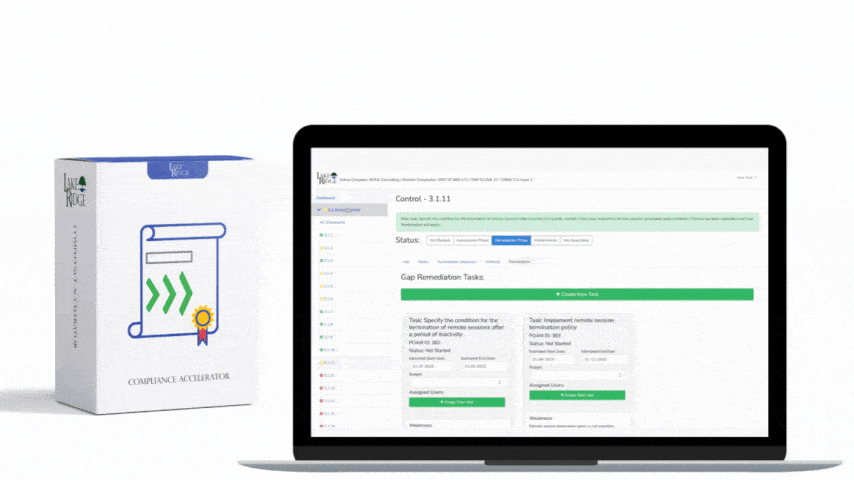
At a high level Control 2-5-2 requires you to collect telemetry across network and hosts, detect suspicious activity in near real time, and have documented procedures to triage and respond to alerts. Implementation begins with an inventory (log sources, network choke points, internet uplinks, cloud VPCs), a design for sensor placement and log collection, and a documented alerting playbook that defines severity, ownership, SLAs and containment actions. For Compliance Framework alignment document each data source, retention period, and the decision logic used to escalate incidents.
SIEM: deployment, log collection and normalization
Choose a SIEM that fits your risk profile and budget: managed cloud SIEM (Splunk Cloud, Elastic Cloud, Chronicle) for low ops cost, or open-source/self-hosted (Wazuh + Elastic, OSSIM) for tighter cost control. On the technical side: collect structured logs (Windows Event, syslog, VPC Flow, firewall logs, VPN) and unstructured logs (application audit). Use TLS/encrypted channels (syslog over TLS, Beats to Elasticsearch with TLS) and enforce NTP across devices to ensure reliable timestamps. Implement agents on servers for process, auth, and file integrity events; use flow logs and Zeek/Suricata metadata for network visibility. Normalize logs into common fields (timestamp, src_ip, dst_ip, user, process, rule_id) so correlation rules can be expressive and repeatable for audits.
SIEM sizing, retention and parsing—practical numbers
Small-business sizing example: 50 users generating ~5–10 GB/day of logs, plus network devices adding 10–20 GB/day = ~25 GB/day. For a 90‑day hot retention estimate 25 GB/day × 90 = 2.25 TB of hot storage (plus overhead for indices ~1.5×). If policy requires 1 year cold retention, plan for an additional ~6.6 TB. When budget constrained, prioritize 90 days for hot searches and archive older logs to cost‑effective object storage. Configure parsers for common formats (CEF, LEEF, JSON) and validate parsing with sample logs—misparses are a common cause of missed detections and failed audits.
IDS/IPS placement, rule management and tuning
Decide where to place sensors: passive IDS on SPAN/mirror ports or network taps at internet uplinks, DMZ boundaries and key east‑west segments; inline IPS only where you have capacity to avoid outages and with fail‑open configured for critical links. Use Zeek for protocol analysis and Suricata or Snort for signature detection. Start with community rule sets (Emerging Threats) and add rules for your environment (eg. block known malicious C2 IPs, detect SMB exfil patterns). Tune aggressively: baseline normal traffic for 2–4 weeks, then disable or tune rules generating >95% false positives. Maintain rule change logs and test rule updates in a staging sensor before pushing to production to satisfy change-control requirements in the Compliance Framework.
Alerting playbook: structure, SLAs and runbooks
Your alerting playbook must be actionable, auditable and realistic. At minimum include: alert severity mapping (Critical/High/Medium/Low), ownership (on‑call SOC or MSSP), initial triage steps, enrichment sources (asset inventory, vulnerability status, EDR telemetry), containment actions, evidence preservation steps, communication templates (internal, customer, regulator), and post‑incident review requirements. Define SLAs: for example, Critical alerts triaged within 15 minutes, containment decision within 60 minutes, and incident declared within 4 hours for breaches affecting sensitive data. Integrate SIEM with ticketing (Jira, ServiceNow) and EDR so that alerts automatically create a ticket with enrichment context (process hashes, DNS queries, network flows) to reduce manual steps.
Example runbook (suspicious outbound SMB traffic)
Example: SIEM rule flags a workstation making SMB connections to an external IP (severity: High). Runbook steps: (1) Triage—verify alert by checking SIEM and EDR process/log correlation (within 15 min). (2) Enrich—retrieve asset owner, last patch date, running processes, and destination IP reputation (15–30 min). (3) Contain—if confirmed, isolate host on the network or apply a temporary firewall block to destination IP (within 60 min). (4) Preserve—collect memory dump and relevant logs to secure storage; record chain of custody. (5) Eradicate & recover—clean malware using EDR, apply patches, validate no persistent backdoors. (6) Post‑incident—create an after‑action with root cause analysis and update detection rules to reduce recurrence. Document timestamps and approvers for each action for compliance evidence.
Small-business scenarios, cost-conscious choices and best practices
Small businesses can meet Control 2-5-2 without enterprise budgets. Example A: a 25‑user accounting firm uses a managed SIEM (Elastic Cloud) with one Suricata sensor on the internet edge and host agents (Wazuh/OSQuery) on critical servers; they forward only critical logs (firewall, VPN, AD auth, EDR alerts) to control costs and keep 90‑day hot retention. Example B: a 100‑employee e‑commerce shop uses cloud-native telemetry (AWS VPC Flow, CloudTrail, GuardDuty) plus an Elastic Cloud deployment for correlation and a lightweight IDS in the VPC for east‑west. Best practices: document data flows and retention to satisfy auditors, enable role-based access to SIEM dashboards, encrypt log storage, conduct quarterly rule tuning and annual tabletop exercises, and keep a concise evidence folder (logs, playbooks, change logs) for Compliance Framework reviews.
Failing to implement continuous monitoring, tuned detection, and a tested alerting playbook increases risk of prolonged undetected breaches, regulatory fines, and loss of customer trust. Without documented procedures you will struggle to demonstrate compliance during audits and will likely face longer mean time to detect (MTTD) and mean time to respond (MTTR), which increases the chance of data exfiltration and business impact.
Summary: to meet ECC‑2:2024 Control 2-5-2, build a prioritized telemetry plan, deploy a SIEM and IDS/IPS suited to your size, enforce secure log transport and time synchronization, tune detection to your baseline, and codify an alerting playbook with SLAs and evidence capture. Start small—focus on critical assets and internet/DMZ boundaries—iterate with regular tuning and tabletop exercises, and maintain documentation mapping each technical control to the Compliance Framework requirements so audits and incident response are efficient and defensible.