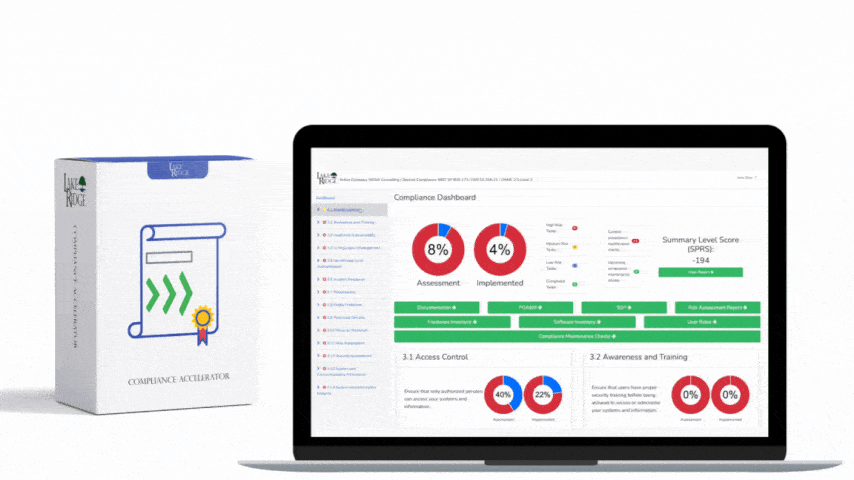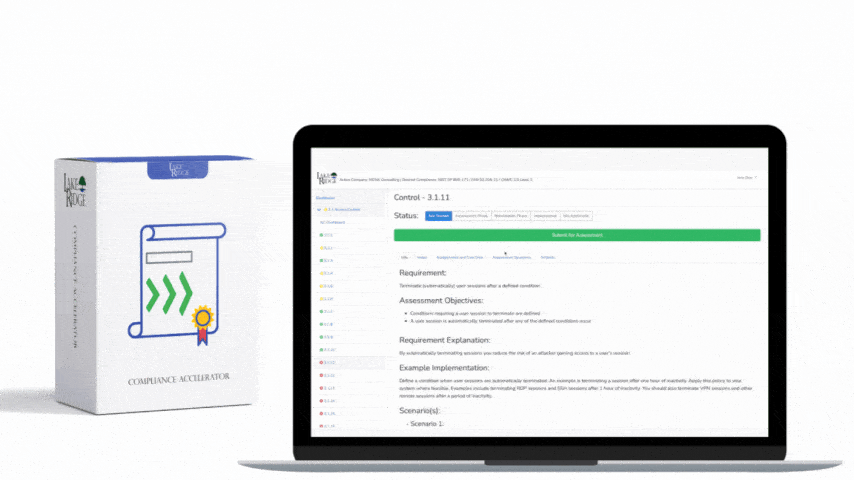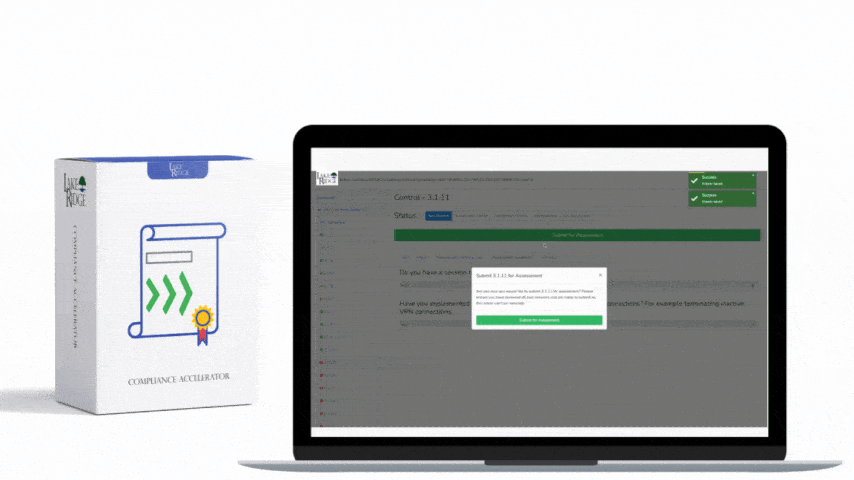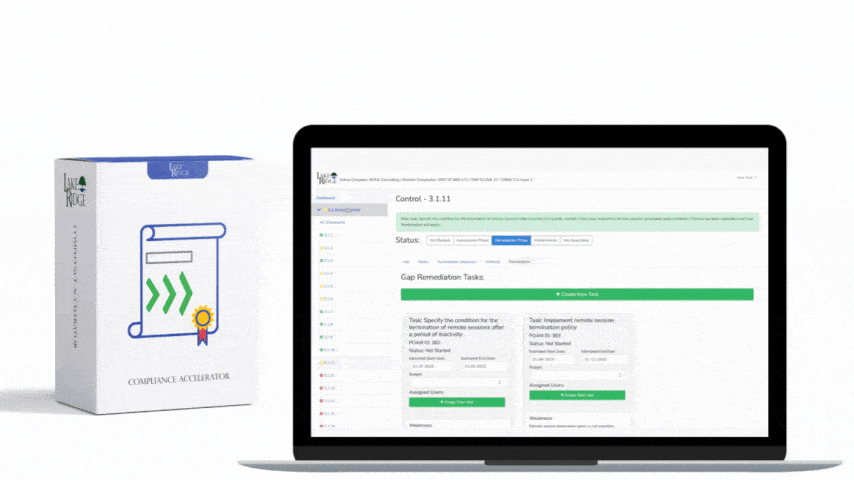
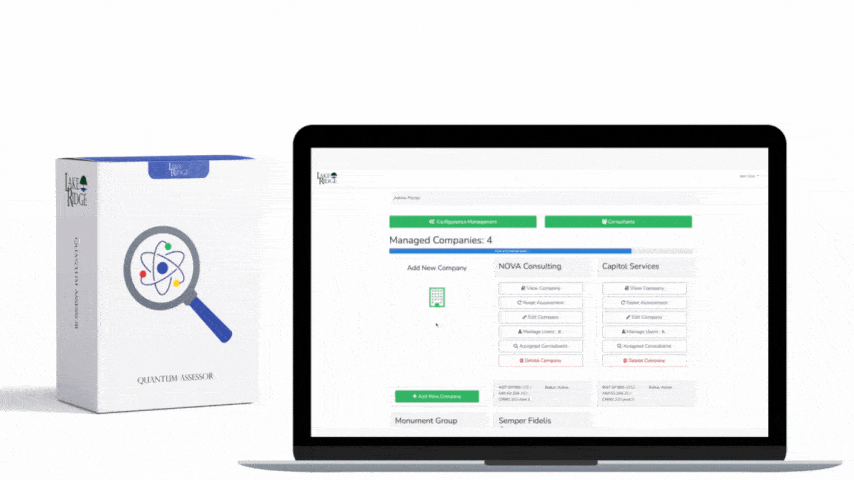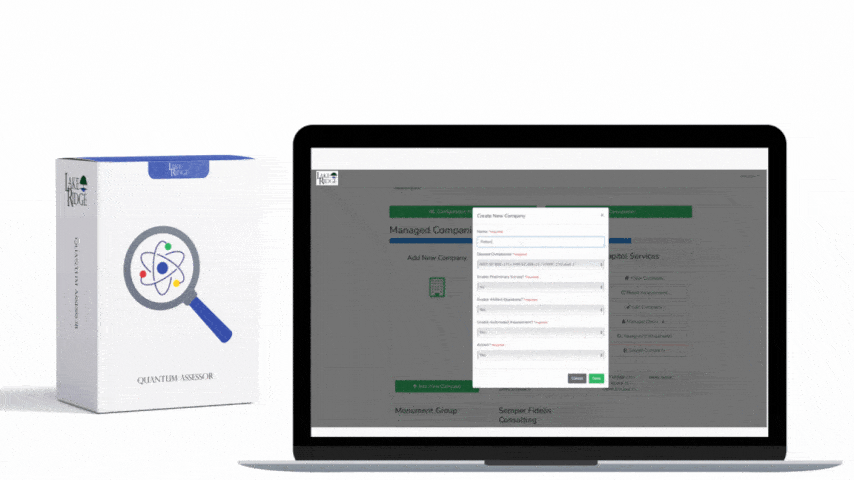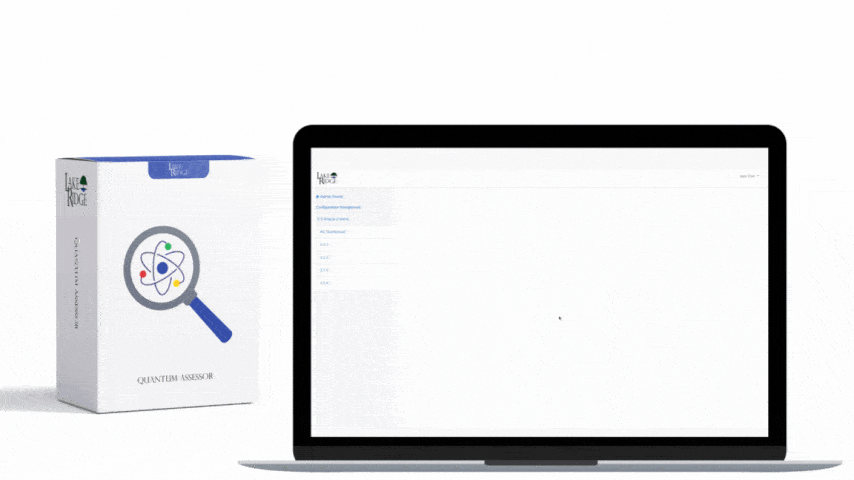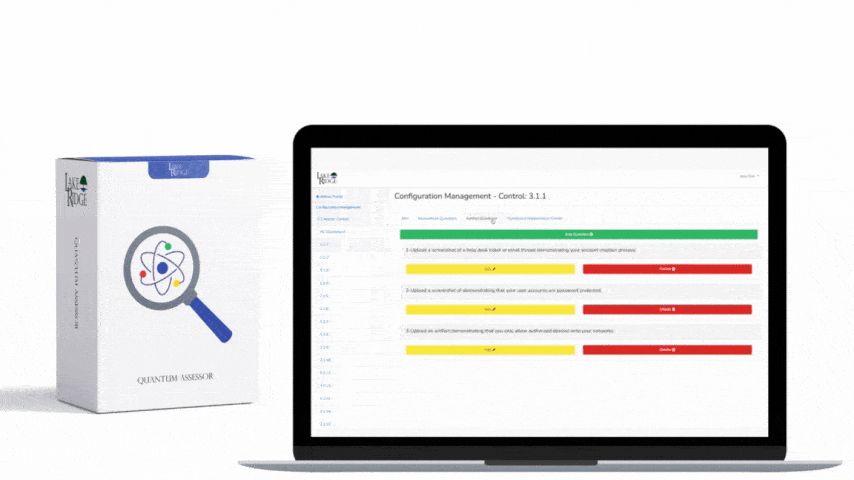
Monitoring external/internal boundaries is a foundational compliance and security practice: it lets operations teams detect unauthorized connections, anomalous data flows, and early signs of compromise that could affect Federal Contract Information (FCI) or Controlled Unclassified Information (CUI) covered by FAR 52.204-21 and CMMC 2.0 Level 1 (SC.L1-B.1.X); this post gives practical, implementable steps to train your ops team and operationalize boundary monitoring in a small-business environment.
What SC.L1-B.1.X and FAR 52.204-21 require in practical terms
At Level 1, CMMC emphasizes basic cyber hygiene: know where your internal network ends and the untrusted world begins, capture evidence of traffic crossing that boundary, and have processes to respond. FAR 52.204-21 similarly requires safeguarding contractor information systems and implementing practices that reasonably secure contractor-held data. For operations teams this translates into: define boundaries, enable boundary logging (firewalls, routers, NGFWs, VPNs, cloud security groups), baseline normal traffic, and escalate deviations to an incident or change process.
Step 1 — Define boundaries and inventory the touchpoints
Actionable start: create a simple boundary inventory spreadsheet that lists every place traffic moves between "trusted/internal" and "untrusted/external" (edge firewall interfaces, VPN concentrators, cloud NAT gateways, third-party SaaS integrations, partner VLANs). For each entry include device/host, interface name, purpose, owner, and logs available (syslog, NetFlow, VPC Flow Logs). Example for a small business: on-prem Ubiquiti firewall (WAN/DMZ/LAN), AWS account with Internet Gateway and Security Groups, and a third-party file-sync SaaS connection — track each as a boundary touchpoint.
Suggested inventory columns
Device name, IP/subnet, boundary direction (ingress/egress/both), logging type & retention, alert owner, and a short rule description (example: "Allow VPN users to internal app servers; log all denied attempts"). This makes audit evidence straightforward to collect and review.
Step 2 — Deploy minimal monitoring stack and logging configurations
Practical technical setup for small shops: ensure edge devices send logs to a central collector (syslog or agent). In cloud, enable VPC Flow Logs (AWS), NSG Flow Logs (Azure), or VNet Flow logs and forward to CloudWatch/Azure Monitor/Log Analytics. On-prem, configure firewall/UTM to send syslog to a lightweight SIEM/collector such as Wazuh, Graylog, or an EDR with network visibility. Configure log formats and a retention policy (practical minimum 90 days for network logs; longer if contract requires). Example iptables logging rule: iptables -A FORWARD -o eth0 -j LOG --log-prefix "FW_EGRESS: " --log-level 4 — and forward /var/log/messages to your collector.
Step 3 — Baselines, detection rules, and alert tuning
Train ops to baseline normal external/internal traffic for 30 days: typical ports (80/443), expected IP peers (vendors), and daily throughput. Then create detection rules such as: unusually large egress volumes to a new external IP, repeated denied connections from a single internal host, or high DNS query rates from a workstation. Example SIEM rule (pseudo): IF sum(bytes_out) by src_ip over 10 minutes > 100 MB to an external host AND host not in approved list THEN generate high-priority alert. Keep thresholds conservative to limit false positives — document tuning decisions in your evidence package.
Step 4 — Playbooks, escalation, and runbooks for operations teams
Operationalize with compact playbooks: for each high-priority alert define owner, triage steps, containment options, and evidence collection steps. Example playbook for "unusual egress to external IP": 1) isolate host VLAN or remove from VPN; 2) collect PCAP or NetFlow slice for 24 hrs; 3) check process list / EDR telemetry; 4) notify CISO/contracting officer if FCI/CUI may be affected; 5) open incident ticket and retain artifacts for 90+ days. Train staff by running tabletop exercises quarterly and one live drill per year — measure time-to-detect (TTD) and time-to-contain (TTC) and aim to improve those metrics.
Small-business tooling and realistic examples
A 20-person company example: use a managed UTM (e.g., a cloud-managed firewall from Fortinet or a Ubiquiti setup) forwarding logs to a low-cost collector like Wazuh running on a single AWS t3.small. Enable AWS CloudTrail and VPC Flow Logs for cloud assets, configure retention to 90 days, and create two priority alerts: anomalous egress (>100 MB in 10 minutes) and VPN auth failures > 10 in 5 minutes. If budget is tight, use free tiers of ELK/Elastic or Splunk light plus open-source sensors (Zeek/Suricata) to capture boundary events; document the mapping of each sensor to the boundary inventory for compliance reviewers.
Risks of not implementing boundary monitoring
Without monitoring, lateral movement and exfiltration can go undetected—small businesses often discover breaches weeks or months later. Consequences include loss of contract, mandated breach notifications, reputational harm, and possible financial penalties. For contractors subject to FAR 52.204-21, failure to document reasonable safeguarding practices can result in contract termination or exclusion from future opportunities. Operationally, lack of monitoring means no measured response times and therefore an inability to prove remediation effectiveness during audits.
Compliance tips and best practices
Keep documentation tight: boundary inventory, log configuration screenshots, SIEM rule definitions, playbooks, and quarterly training records. Automate evidence collection where possible (export reports naming conventions and timestamps). Use change control to approve any rule that opens a boundary and record rationale. Favor managed services for small teams to reduce operational overhead, but validate that the managed provider supplies the log types you need. Finally, review and re-baseline after any major change (new cloud workload, acquired office, or new SaaS vendor).
Summary: operationalizing boundary monitoring for FAR 52.204-21 and CMMC 2.0 Level 1 is achievable for small businesses with a clear inventory, a minimal logging stack, tuned detection rules, compact playbooks, and regular training; follow the steps above, document everything, and prioritize automation and managed services where they lower risk and cost.