This post explains how to implement the SI.L2-3.14.6 requirement from NIST SP 800-171 Rev.2 / CMMC 2.0 Level 2 by using a SIEM and detection rules to reliably identify Indicators of Attack (IoAs), with practical, actionable steps and real-world examples targeted to small businesses operating under the Compliance Framework.
Understanding SI.L2-3.14.6 and what you're required to do
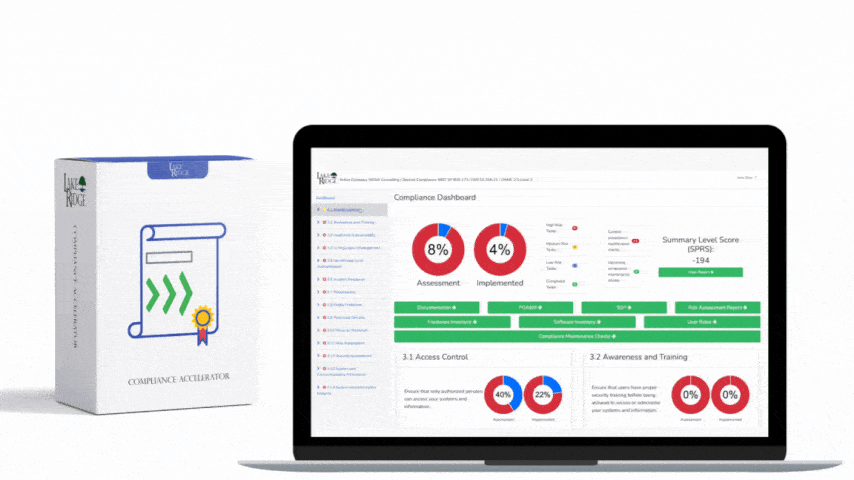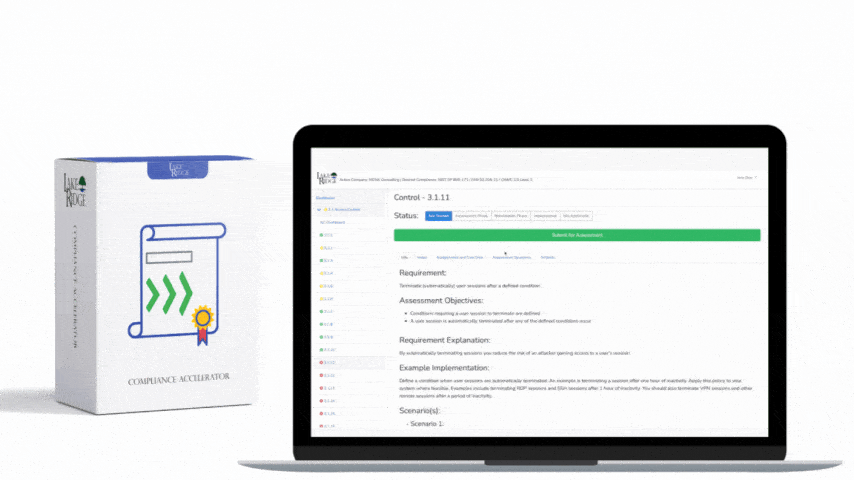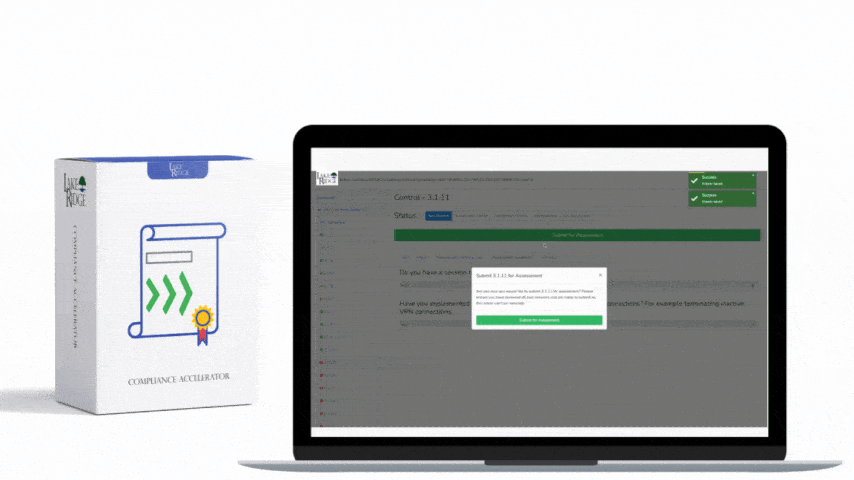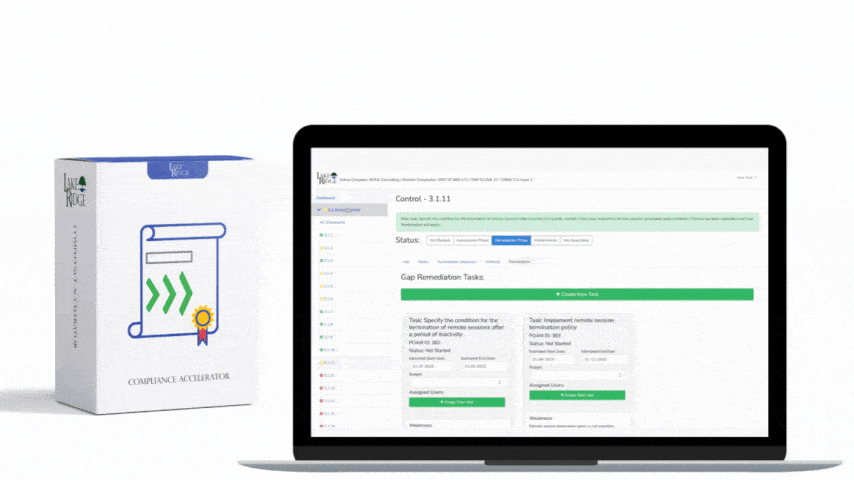
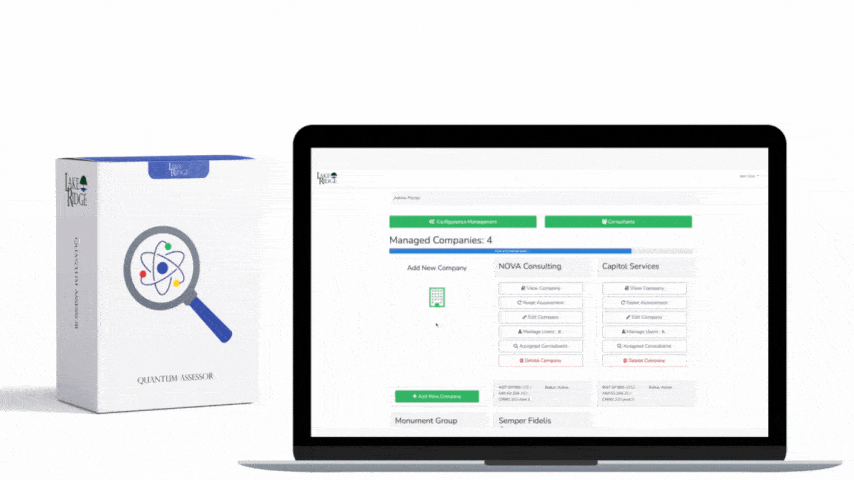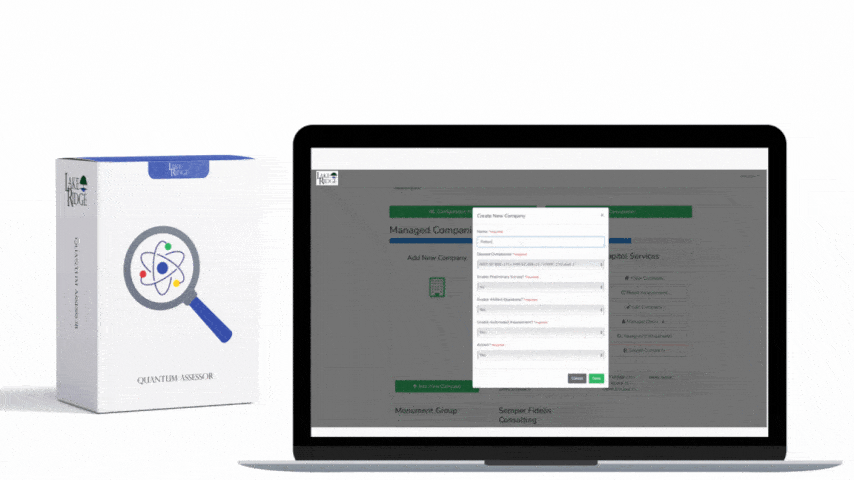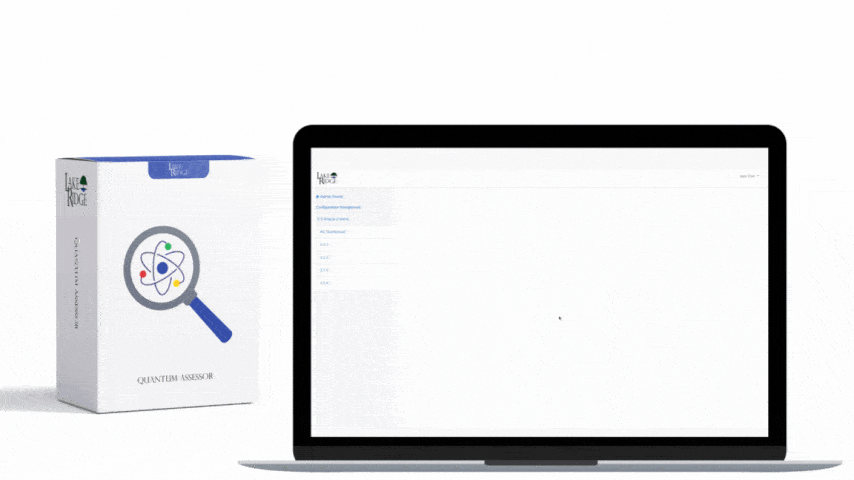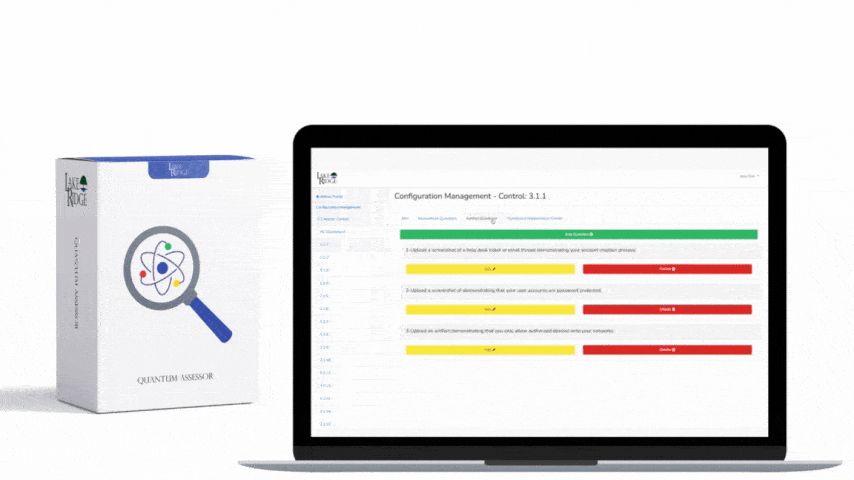
SI.L2-3.14.6 requires organizations to detect and identify indicators of attack leveraging monitoring, detection, and related tooling so that potential compromises are found early. For Compliance Framework implementation, interpret this as a mandate to (1) instrument critical assets to provide relevant telemetry, (2) ingest that telemetry into a SIEM or managed detection platform, and (3) implement and maintain detection rules that map to known attacker behaviors (not just signatures). The goal is behavioral detection, enriched context for triage, and documented proof of detection coverage for CMMC assessment.
Key log sources and telemetry to ingest (practical specifics)
Start by prioritizing telemetry that produces high-fidelity IoAs: Windows Security logs (EventIDs 4624/4625/4688 for logon and process creation), Sysmon events (1-process create, 3-network connection, 7-image loaded, 10-process access), endpoint detection & response (EDR) process and kernel events, firewall and VPN logs, DNS and proxy logs, cloud audit logs (AWS CloudTrail, Azure Activity/Sign-in logs), mail gateway logs, and DLP alerts. For Linux hosts collect auditd/syslog and process command line; for containers collect kube-audit and cloud-native control plane logs. For a small business, prioritize Windows/EDR + perimeter (firewall/proxy) + cloud provider logs first — these generally give the most bang for buck.
Designing effective detection rules — practical examples
Build rules that combine multiple telemetry types and map to MITRE ATT&CK techniques. Examples: detect suspicious PowerShell: a rule that flags a Windows process creation event where parent process is powershell.exe or cmd.exe and command line contains "-EncodedCommand" or "IEX (New-Object Net.WebClient)"; Splunk-style pseudo-query: "index=wineventlog EventCode=4688 CommandLine='*-EncodedCommand*' OR CommandLine='*IEX*Net.WebClient*' | stats count by host, user, CommandLine". Detect lateral movement attempts by correlating failed SMB logons (event 4625) from a host followed by successful network logon to another host within 5 minutes. Detect DNS exfil by counting high-volume unique subdomain queries per host per hour and flag if > 1000 unique subdomains. For Linux, detect suspicious privilege escalation by alerting on "sudo" failures followed by successful root shells or creation of new local accounts.
Implementation advice for small businesses (tactical steps)
If you lack internal SOC staff, use a managed SIEM/MSSP to ingest and normalize logs (Winlogbeat/Elastic or syslog/CEF). Start with a minimum viable detection set: credential brute force (repeated failed logons), abnormal PowerShell/command-line execution, creation of scheduled tasks and remote service installs, outbound data transfers to uncommon DNS domains/HTTP POST endpoints, and privilege escalation events. Instrument Sysmon on Windows endpoints (with a focused config), ensure EDR is forwarding process and network connection events to the SIEM, forward firewall and VPN logs, and enable CloudTrail/AzureActivity. Set log retention to cover investigation needs — a practical start is 90 days hot/365 days cold depending on cost and contractual obligations — and document retention policies for assessments.
Sample detection logic and tuning
Keep rules simple then iterate: initially alert on behavior patterns (e.g., "more than 10 failed logins across >=3 hosts from the same external IP within 30 minutes") rather than single noisy events. Use enrichment (GeoIP, user-to-host mappings, asset criticality tags) to raise or suppress alerts. Example Elastic-style KQL: "event.action:authentication_failure AND source.ip: * AND host.os.platform: windows | aggregate by source.ip, count>20 timeframe=1h". After 2–4 weeks of baseline data, tune thresholds to reduce false positives, and add allow-lists for known maintenance IPs and scheduled automation tools.
Alerting, triage, and incident playbooks
Create short playbooks for each detection rule that list: required triage fields (host, user, process command-line, source IP, timeline), initial containment steps (isolate host in EDR, block IP at firewall), enrichment steps (WHOIS, reverse DNS, passive DNS), and escalation criteria. Automate repetitive triage where safe (IOC enrichment, host check-in status) using SOAR or playbooks in the SIEM. For small teams, a 5-step triage checklist (validate, enrich, contain, eradicate, recover) tied to each alert dramatically speeds response and helps demonstrate compliance during assessments.
Tuning, testing, and continuous improvement
Threat hunting and regular rule testing are necessary to maintain coverage. Run quarterly simulated attacks (e.g., use open-source red-team tools like Atomic Red Team or Caldera) targeting the most likely techniques against your environment and measure detection rates. Track metrics such as Mean Time To Detect (MTTD), number of true vs. false positives per rule, and coverage gaps by asset. Maintain a prioritized backlog: add or refine rules that detect high-risk behaviors targeting CUI, and retire rules that consistently yield low value. Keep evidence of testing, tuning notes, and rule justification for auditors.
Risks of not implementing SI.L2-3.14.6
Failure to implement this control leaves your organization blind to attacker activity until late in the kill chain. Risks include undetected credential theft, lateral movement, data exfiltration of Controlled Unclassified Information (CUI), loss of federal contracts, failed CMMC assessments, and reputational or financial harm. Small businesses are attractive targets because they often lack detection; without SIEM-driven detection you rely solely on chance or external notification to learn of a compromise.
In summary, meeting SI.L2-3.14.6 means building a practical SIEM program that prioritizes high-fidelity telemetry, implements behavior-based detection rules mapped to known attacker techniques, and documents tuning, testing, and playbooks. For small businesses: prioritize Windows/EDR + perimeter + cloud logs, begin with a compact set of high-value detections, use managed services if needed, and perform regular testing and tuning so detection capability remains effective and auditable under the Compliance Framework.